
Моменты распределения
Центральное значение, или расположение распределения, — первое, что надо знать о группе данных. Следующая величина, которая представляет интерес, — это изменчивость данных, или «ширина» относительно центрального значения.Мы назовем значение центральной тенденции первым моментом распределения.
Изменчивость точек данных относительно центральной тенденции называется вторым моментом распределения. Следовательно, второй момент измеряет разброс распределения относительно первого момента.
Как и в случае с центральной тенденцией, существует много способов измерения разброса. Далее мы рассмотрим семь из них, начиная с наименее распространенных вариантов и заканчивая самыми распространенными.
Широта (range) распределения — это просто разность между самым высоким и самым низким значением распределения. Таким же образом широта перцентиля 10-90 является разностью между 90-й и 10-й точками. Эти первые две величины измеряют разброс по крайним точкам. Остальные пять измеряют отклонение от центральной тенденции (т.е. измеряют половину разброса).
Семи-интерквартильная широта (sem-interquartile range), или квартальное отклонение (quartile deviation), равна половине расстояния между первым и третьим квартилями (25-й и 75-й перцентили). В отличие от широты перцентиля 10-90, здесь широта делится на два.
Полуширина (half-width) является наиболее распространенным способом измерения разброса. Сначала надо найти высоту распределения в его пике (моде), затем найти точку в середине высоты и провести через нее горизонтальную линию перпендикулярно вертикальной линии. Горизонтальная линия пересечет кривую распределения в одной точке слева и в одной точке справа. Расстояние между этими двумя точками называется полушириной.
Среднее абсолютное отклонение (mean absolute deviation), или просто среднее отклонение, является средним арифметическим абсолютных значений разности значения каждой точки и среднего арифметического значений всех точек. Другими словами (что и следует из названия), это среднее расстояние, на которое значение точки данных удалено от среднего. В математических терминах:
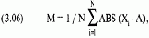
где М = среднее абсолютное отклонение;
N = общее число точек данных;
X. = значение, соответствующее точке i;
А = среднее арифметическое значений точек данных;
ABS() = функция абсолютного значения.
Уравнение (3.06) дает нам совокупное среднее абсолютное отклонение. Вам следует знать, что можно рассчитать среднее абсолютное отклонение по выборке. Для расчета среднего абсолютного отклонения выборки замените 1 / N в уравнении (3.06) на 1 / (N - 1). Используйте эту версию, когда расчеты ведутся не по всей совокупности данных, а по некоторой выборке.
Самыми распространенными величинами для измерения разброса являются дисперсия и стандартное отклонение. Как и в случае со средним абсолютным отклонением, их можно рассчитать для всей совокупности и для выборки. Далее показана версия для всей совокупности данных, которую можно легко переделать в выборочную версию, заменив l/NHal/(N-l). Дисперсия (variance) чем-то напоминает среднее абсолютное отклонение, но при расчете дисперсии каждая разность значения точки данных и среднего значения возводится в квадрат. В результате, нам не надо брать абсолютное значение каждой разности, так как мы автоматически получаем положительный результат, независимо от того, была эта разность отрицательной или положительной. Кроме того, так как в квадрат возводится каждая из этих величин, крайние выпадающие значения оказывают большее влияние на дисперсию, а не на среднее абсолютное отклонение. В математических терминах:
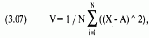
где V = дисперсия;
N = общее число точек данных;
X. = значение, соответствующее точке i;
А = среднее арифметическое значений точек данных.
Стандартное отклонение (standard deviation) тесно связано с дисперсией (и, следовательно, со средним абсолютным отклонением). Стандартное отклонение является квадратным корнем дисперсии.
Третий момент распределения называется асимметрией (skewness), и он описывает асимметричность распределения относительно среднего значения (рисунок 3-2). В то время как первые два момента распределения имеют размерные величины (то есть те же единицы измерения, что и измеряемые параметры), асимметрия определяется таким способом, что получается безразмерной. Это просто число, которое описывает форму распределения.
Положительное значение асимметрии означает, что хвосты больше с положительной стороны распределения, и наоборот. Совершенно симметричное распределение имеет нулевую асимметрию.
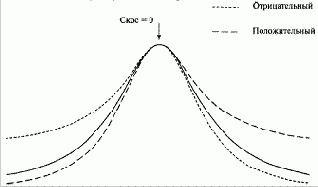
Рисунок 3-2 Асимметрия
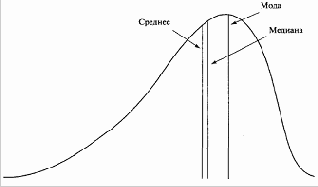
Рисунок 3-3 Асимметричное распределение
В симметричном распределении среднее, медиана и мода имеют одинаковое значение. Однако когда распределение имеет ненулевое значение асимметрии, оно может принять вид, показанный на рисунке 3-3. Для асимметричного распределения (любого распределения с ненулевой асимметрией) верно равенство:
(3.08) Среднее - Мода = 3 * (Среднее - Медиана)
Есть много способов для расчета асимметрии, и они часто дают различные ответы.
Ниже мы рассмотрим несколько вариантов:
(3.09) S == (Среднее - Мода) / Стандартное отклонение
(3.10) S = (3 * (Среднее - Медиана)) / Стандартное отклонение
Уравнения (3.09) и (3.10) дают нам первый и второй коэффициенты асимметрии Пирсона. Асимметрия также часто определяется следующим образом:
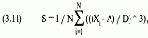
где S = асимметрия;
N = общее число точек данных;
Х = значение, соответствующее точке i;
А = среднее арифметическое значений точек данных;
D = стандартное отклонение значений точек данных.
И наконец, четвертый момент распределения, эксцесс (kurtosis) (см. рисунок 3-4), измеряет, насколько у распределения плоская или острая форма (по сравнению с нормальным распределением). Как и асимметрия, это безразмерная величина.
Кривая, менее остроконечная, чем нормальная, имеет эксцесс отрицательный, а кривая, более остроконечная, чем нормальная, имеет эксцесс положительный.
Когда пик кривой такой же, как и у кривой нормального распределения, эксцесс равен нулю, и мы будем говорить, что это распределение с нормальным эксцессом.
Как и предыдущие моменты, эксцесс имеет несколько способов расчета. Наиболее распространенными являются:
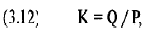
где К = эксцесс;
Q == семи-интерквартильная широта;
Р = широта перцентиля 10-90.
(3.13) К = (1 / N (Σ (((X - Аi) / D)^ 4))) - 3,
где К = эксцесс;
N = общее число точек данных;
Х = значение, соответствующее точке i;
А = среднее арифметическое значений точек данных;
D = стандартное отклонение значений точек данных.
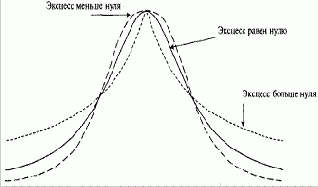
Рисунок 3-4 Эксцесс
Наконец, необходимо отметить, что «теория», связанная с моментами распределения, намного серьезнее, чем то, что представлено здесь. Для более глубокого понимания вам следует просмотреть книги по статистике, упомянутые в списке рекомендованной литературы. Для наших задач изложенного выше вполне достаточно.
До настоящего момента рассматривалось распределение данных в общем виде.
Теперь мы изучим нормальное распределение.
Содержание раздела