
Пример 1: Оценка теста вне пределов выборки
Оценка оптимизированной системы на данных, взятых вне пределов выборки и ни разу не использованных при оптимизации, аналогична оценке неоптимизированной системы. В обоих случаях проводится один тест без подстройки параметров. В табл. 4- 1 показано применение статистики для оценки неоптимизированной системы. Там приведены результаты проверки на данных вне пределов выборки совместно с рядом статистических показателей. Помните, что в этом тесте использованы свежие данные, которые не применялись как основа для настройки параметров системы.Параметры торговой модели уже были определены. Образец данных для оценки вне пределов выборки охватывает период с 1.01.1995 г. По 1.01.1997 г.; модель тестировалась на этих данных и совершала смоделированные сделки. Было проведено 47 сделок. Этот набор сделок можно считать выборкой сделок, т.е. частью популяции смоделированных сделок, которые система совершила бы по данным правилам в прошлом или будущем. Здесь возникает вопрос по поводу оценки показателя средней прибыли в сделке — могло ли данное значение быть достигнуто за счет чистой случайности? Чтобы найти ответ, потребуется статистическая оценка системы.
Чтобы начать оценку системы, для начала нужно рассчитать среднее в выборке для n сделок. Среднее здесь будет просто суммой прибылей/убытков, поделенной на n (в данном случае 47). Среднее составило $974,47 нем не требуются поправки на оптимизацию или множественные тесты. Система представляет собой модель торговли индексом S&P 500, основанную на лунном цикле, и была опубликована нами ранее (Katz, McCormick, июнь 1997).
Стандартное отклонение (изменчивость показателей прибылей/убытков) рассчитывается после этого вычитанием среднего из каждого результата, что дает 47 (n) отклонений. Каждое из значений отклонения возводится в квадрат, все квадраты складываются, сумма квадратов делится на n — 1 (в данном случае 46), квадратный корень от результата и будет стандартным отклонением выборки. На основе стандартного отклонения выборки вычисляется ожидаемое стандартное отклонение прибыли в сделке: стандартное отклонение (в данном случае $6091,10) делится на квадратный корень из n. В нашем случае ожидаемое стандартное отклонение составляет $888,48.
Чтобы определить вероятность случайного происхождения наблюдаемой прибыли, проводится простая проверка по критерию Стьюдента.
Поскольку прибыльность выборки сравнивается с нулевой прибыльностью, из среднего, вычисленного выше, вычитается ноль, и результат делится на стандартное отклонение выборки для получения значения критерия t , в данном случае— 1,0968. В конце концов оценивается вероятность получения столь большого t по чистой случайности. Для этого рас-
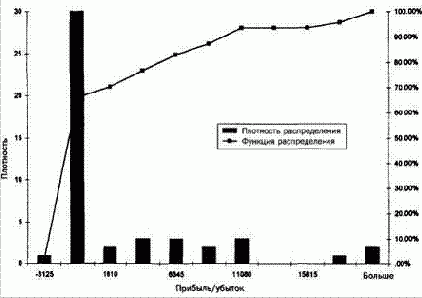
Рисунок 4- 1. функция и плотность распределения вероятностей для сделок в пределах выборки.
считывается функция распределения t для данных показателей с количеством степеней свободы, равным n— 1 (или 46).
Программа работы с таблицами Microsoft Excel имеет функцию вычисления вероятностей на основе t- распределения. В сборнике Numerical Recipes in С приведены неполные бета- функции, при помощи которых очень легко рассчитывать вероятности, основанные на различных критериях распределения, включая критерий Стьюдента. Функция распределения Стьюдента дает показатели вероятности случайного происхождения результатов системы. Поскольку в данном случае этот показатель был мал, вряд ли причиной эффективности системы была подгонка под случайные характеристики выборки. Чем меньше этот показатель, тем меньше вероятность того, что эффективность системы обусловлена случаем.
В данном случае показатель был равен 0,1392, т.е. при испытании на независимых данных неэффективная система показала бы столь же высокую, как и в тесте, прибыль только в 14% случаев.
Хотя проверка по критерию Стьюдента в этом случае рассчитывалась для прибылей/убытков, она могла быть с равным успехом применена, например, к выборке дневных прибылей. Дневные прибыли именно так использовались в тестах, описанных в последующих главах. Фактически, соотношение риска/прибыли, выраженное в процентах годовых, упоминаемое во многих таблицах и примерах представляет собой t- статистику дневных прибылей.
Кроме того, оценивался доверительный интервал вероятности выигрышной сделки. К примеру, из 47 сделок было 16 выигрышей, т.е. процент прибыльных сделок был равен 0,3404. При помощи особой обратной функции биноминального распределения мы рассчитали верхний и нижний 99%- ные пределы. Вероятность того, что процент прибыльных сделок системы в целом составит от 0,1702 до 0,5319 составляет 99%. В Excel для вычисления доверительных интервалов можно использовать функцию CRITBINOM.
Различные статистические показатели и вероятности, описанные выше, должны предоставить разработчику системы важную информацию о поведении торговой модели в случае, если соответствуют реальности предположения о нормальном распределении и независимости данных в выборке. Впрочем, чаще всего заключения, основанные на проверке по критерию Стьюдента и других статистических показателях, нарушаются; рыночные данные заметно отклоняются от нормального распределения, и сделки оказываются зависимыми друг от друга. Кроме того, выборка данных может быть непредставительной. Означает ли это, что все вышеописанное не имеет смысла? Рассмотрим примеры.
Что, если распределение не соответствует нормальному?
При проведении проверки по критерию Стьюдента исходят из предположения, что данные соответствуют нормальному распределению. В реальности распределение показателей прибылей и убытков торговой системы таким не бывает, особенно при наличии защитных остановок и целевых прибылей, как показано на рис. 4- 1. Дело в том, что прибыль выше, чем целевая, возникает редко. Фактически большинство прибыльных сделок будут иметь прибыль, близкую к целевой. С другой стороны, кое- какие сделки закроются с убытком, соответствующим уровню защитной остановки, а между ними будут разбросаны другие сделки, с прибылью, зависящей от методики выхода. Следовательно, это будет совсем непохоже на колоколо образную кривую, которая описывает нормальное распределение. Это составляет нарушение правил, лежащих в основе проверки по критерию Стьюдента. Впрочем, в данном случае спасает так называемая центральная предельная теорема: с ростом числа точек данных в выборке распределение стремится к нормальному. Если размер выборки составит 10, то ошибки будут небольшими; если же их будет 20 — 30, ошибки будут иметь исчезающе малое значение для статистических заключений. Следовательно, многие виды статистического анализа можно с уверенностью применять при адекватном размере выборки, например при n = 47 и выше, не опасаясь за достоверность заключений.
Что, если существует серийная зависимость? Более серьезным нарушением, способным сделать неправомочным вышеописанное применение проверки по критерию Стьюдента, является серийная зависимость — случай, когда данные в выборке не являются независимыми друг от друга. Сделки совершаются в виде временного ряда. Последовательность сделок, совершенных в течение некоторого периода времени, нельзя назвать случайной выборкой — подлинно случайная выборка состояла бы, например, из 100 сделок, выбранных случайным образом из всей популяции данных — от начала рынка (например, 1983 г. для S&P 500) до отдаленного будущего. Такая выборка не только была бы защищена от серийной зависимости, но и являлась бы более представительной для популяции.
Однако при разработке торговых систем выборка сделок обычно производится на ограниченном временном отрезке; следовательно, может наблюдаться корреляция каждой сделки с соседними, что сделает данные зависимыми.
Практический эффект этого явления состоит в уменьшении размеров выборки. Если между данными существует серийная зависимость, то, делая статистические выводы, следует считать, что выборка в два или в четыре раза меньше реального количества точек данных. Вдобавок определить достоверным образом степень зависимости данных невозможно, можно только сделать грубую оценку — например, рассчитав серийную корреляцию точки данных с предшествующей и предыдущей точками.
Рассчитывается корреляция прибыли/убытка сделки i и прибыли/убытка сделок i + 1 и i — 1. В данном случае серийная корреляция составила 0,2120. Это немного, но предпочтительным было бы меньшее значение.
Можно также рассчитать связанный t- критерий для статистической значимости значения корреляции. В данном случае выясняется, что если бы в популяции действительно не было серьезной зависимости, то такой уровень корреляции наблюдался бы только в 16% тестов.
Серийная зависимость — серьезная проблема. Если она высока, то для борьбы с ней надо считать выборку меньшей, чем она есть на самом деле.
Другой вариант — выбрать случайным образом данные для тестирования из различных участков за длительный период времени. Это также повысит представительность выборки в отношении всей популяции.
Что, если изменится рынок? При разработке торговых систем возможно нарушение третьего положения t- критерия, и его невозможно предугадать или компенсировать. Причина этого нарушения в том, что популяция, из которой взят образец данных для тестирования или разработки, может отличаться от популяции, данные из которой будут использоваться в будущих сделках. Рынок может подвергаться структурным или иным изменениям. Как говорилось, популяция данных S&P 500 до 1983 г. принципиально отличается от последующих данных, когда началась торговля опционами и фьючерсами. Подобные события могут разрушить любой метод оценки системы. Как бы ни проводилось тестирование, при изменении рынка до начала реальной торговли окажется, что система разрабатывалась и тестировалась на одном рынке, а работать будет на другом.
Естественно, модель разваливается на части. Даже самая лучшая модель будет уничтожена изменением рынка.
Тем не менее большинство рынков постоянно меняются. Несмотря на этот суровый факт, использование статистики в оценке системы остается принципиально важным, поскольку если рынок не изменится вскоре после начала работы системы или же изменения рынка недостаточны, чтобы оказать глубокое влияние, то статистически возможно произвести достаточно достоверную оценку ожидаемых вероятностей и прибылей системы.
Содержание раздела