
Пути построения адекватных моделей
В него включаются все известные переменные, которые с содержательной точки зрения могут оказаться значимыми. В окончательном варианте исследователь ограничивается конечным и, как правило, небольшим числом переменных. За пределами его внимания по разным причинам остается большое число переменных, связанных друг с другом отношениями влияния. Таким образом, реально исследователь всегда рассматривает часть (или несколько частей) некоторой схемы влияния.
Преобразуя графы, можно уменьшить размерность набора переменных, не искажая структуры причинно-следственных связей оставшихся переменных. Другими словами, используя операции над графом, можно выделить необходимую часть структуры таким образом, чтобы связи, опосредованные исключаемыми характеристиками новой структуры,
сохранились.
Преобразование пространства признаков состоит в отборе существенных факторов. В процессе моделирования приходится разрешать противоречие между многомерностью экономических явлений, связанных между собой, и стремлением упростить модель с целью выделения наиболее существенных связей. В модель должны быть включены все факторы, которые с содержательных позиций оказывают влияние на зависимую переменную.
Но в то же время их количество не должно быть слишком большим. Таким образом, исходное пространство признаков должно подвергаться предварительному анализу и преобразованию с целью уменьшения числа переменных, включаемых в модель.
Необходимость и целесообразность такого преобразования объясняется тем, что анализ взаимосвязи признаков и их группировка дают дополнительную содержательную информацию, позволяют выявить определенные закономерности в описании объекта, более обоснованно подойти к формированию модели и оценке ее оптимального размера.
Принципиальная и практическая необходимость снижения размерности признакового пространства обусловлена рядом обстоятельств. Во-первых, возникает необходимость устранения явления мультиколлинеарности.
Во-вторых, необходимо учитывать максимально возможное для данных условий число переменных модели. Конечное число переменных должно быть в несколько раз меньше числа единиц наблюдения.
Наконец, необходимость снижения размерности признакового пространства обусловливается соображениями удобства построения и последующей интерпретации модели.
Конечная цель решения задачи минимизации описания более глубока, чем простое представление большого массива исходных данных: коль скоро удалось коротко представить обширную информацию, то появляется уверенность, что вскрыта некоторая объективная закономерность, существующая в структуре признакового пространства и позволяющая провести это сокращение.
Методические подходы к выбору существенных признаков зависят от того, на какой стадии моделирования они осуществляются. Процесс выбора существенных признаков не заканчивается на стадии предварительного анализа информации, а продолжается в процессе построения экономико-статистической модели.
Однако идеи, лежащие в основе выбора существенных признаков на этих двух стадиях экономико-статистического исследования, различны.
На этапе предварительного анализа сужение набора переменных производится исходя из внутренних свойств пространства признаков и учета их взаимосвязи. При этом отбор и упорядочение признаков основаны на оценке их относительной важности для характеристики единицы совокупности независимо от специфической цели исследования и типа используемого в дальнейшем математического аппарата моделирования.
Критерий выбора информативной подсистемы признаков в ходе построения модели учитывает конкретную цель исследования и специфику используемых методов моделирования. Этот критерий помимо учета взаимосвязи переменных основан на оценке важности отдельных признаков для аппроксимации и прогнозирования моделируемого показателя, учета их влияния на точность модели.
Можно выделить следующие типичные задачи анализа и преобразования исходного пространства признаков:
а) редукция описания объекта непосредственно в ходе корреляционно-регрессионного анализа;
б) группировка признаков, состоящая в выделении групп тесно связанных между собой признаков с последующим выбором представителей групп. Она может быть дополнена требованием формирования групповых факторов вместо выбора представителей групп. Возможна модификация этой задачи, заключающаяся в выделении относительно независимых групп признаков;
в) снижение размерности признакового пространства, основанное на переходе к новым координатам, замене исходных признаков их линейными комбинациями.
Рассмотрим более подробно каждую задачу с учетом не только преимуществ, но и ограничений результатов ее решения.
Одна из существенных трудностей (9) многофакторного регрессионного анализа - наличие мультиколлинеарности, то есть линейных связей между независимыми переменными. Явная мультиколлинеарность обнаруживается при высоких значениях парных коэффициентов (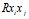 0,7).
0,7).
В этом случае один из признаков должен быть исключен из анализа. Вопрос о том, какую переменную исключить, решается на основе сравнения Ryxi с Ryxj (оставляют переменную с большим значением Ryx) и целей анализа. Однако даже при исключении сильно коррелированных признаков общий суммарный эффект мультиколлениарности может оказаться довольно существенным при сравнительно малых значениях Rxixj. Это проблема методического уровня.
Но и в методологическом плане статистические методы не могут определить меры полностью изолированного влияния факторов, так как роль факторов проявляется только в их взаимодействии. Возможно получение не чистой оценки действия факторов, а выявление значимости каждого из них в определенной структуре.
Это накладывает известные ограничения на интерпретацию и использование результатов анализа.
Задача группировки признаков сводится к выявлению на основе анализа структуры матрицы данных групп тесно связанных между собой признаков и выбора затем из каждой группы признаков-представителей для использования их при построении модели. Это позволяет существенно сократить размерность исходного признакового пространства.
Кроме того, анализ структуры связей и формирование групп тесно связанных признаков представляет самостоятельный интерес, так как позволяют выявить определенные объективные закономерности в структуре пространства признаков, что дает дополнительную ценную с содержательных позиций информацию для выбора переменных модели.
Дело в том, что существует достаточно много способов прямого определения информативного набора признаков для регрессионной модели. С их помощью непосредственно из исходного набора можно получить сокращенный набор максимальной информативности. Однако прямые методы выбора информативного набора представляют собой формализованные процедуры и набор максимальной информативности не всегда будет наилучшим с содержательной точки зрения.
Между тем, имея результаты анализа структуры связей признаков, можно подобрать из тех же групп другие, более характерные признаки и при очень небольшой потере в аппроксимирующей способности сконструировать более совершенные с позиций качественного анализа модели.
Основной причиной широкого распространения методов группировки признаков в экономико-статистических исследованиях является то, что в качестве представителей групп выступают сами исходные признаки. Тем самым снимается проблема интерпретации, которая возникает при использовании методов факторного анализа и других подобных подходов.
К недостаткам метода группировки признаков следует отнести определенные потери информации, особенно если сформированы группы со сравнительно небольшим уровнем тесноты внутригрупповых связей.
Кроме того, отобранные таким способом признаки-представители не являются ортогональными, хотя взаимосвязь между ними очень часто слаба.
В случае использования симметричных матриц связи решение задачи группировки признаков сводится по существу к диагонализации матрицы: в преобразованной матрице вдоль главной диагонали выделяются блоки с большими элементами (значениями показателей силы связи), а элементы, расположенные вне блоков, относительно малы.
Признаки, входящие в одну группу, обладают большей силой связи между собой, чем признаки, принадлежащие к разным группам. Существует целый ряд алгоритмов решения задачи диагонализации: от эвристических до строго формальных.
Помимо описанных методов группировки признаков для снижения размерности признакового пространства можно использовать процедуры факторного и компонентного анализа.
Существо методов факторного анализа (7) состоит в переходе от описания некоторого множества изучаемых объектов, заданного большим набором косвенных, непосредственно измеряемых признаков, к описанию меньшим числом максимально информативных глубинных переменных, отражающих наиболее существенные свойства явления. Такого рода переменные, называемые факторами, являются некоторыми функциями исходных признаков.
Описание фактора отыскивается в виде так называемой факторной матрицы или матрицы факторных нагрузок A размерностью n х m
(n - число признаков, m - число факторов), которая строится на основе матрицы парных корреляций R размерностью n х n. Корреляционная матрица отражает степень взаимосвязи между каждой парой признаков; факторная матрица характеризует степень связи между каждым из n рассматриваемых признаков и m факторами, выявленными в процессе анализа. При этом число m факторов выбирается исходя из двух условий: m должно быть много меньше n, а уровень потерь информации достаточно мал.
Факторная матрица позволяет выделить для каждого фактора группу параметров, наиболее тесно с ним связанных. Тем самым открывается возможность сопоставить факторы друг с другом, дать им содержательное толкование и наименование, то есть осуществить интерпретацию факторов.
Преобразование корреляционной матрицы в факторную не является однозначным. Для выбора факторной матрицы, на основе которой будет проводиться интерпретация факторов, разрабатываются специальные приемы. Обычно выбирается та матрица, в которой исходные параметры сильно связаны с одним из факторов и слабо связаны со всеми
другими.
Общая идея методов факторного анализа состоит в следующем.
Требуется, чтобы данная система исходных параметров была хорошо представлена (описана, аппроксимирована) с помощью некоторой системы факторов. Для этого строится критерий (последовательность критериев), имеющий смысл степени качества представления данной системой факторов системы исходных параметров. Значение критерия можно определить по матрице факторных нагрузок.
После того как такой критерий построен, задача о нахождении искомой матрицы факторных нагрузок ставится как задача экстремизации построенного критерия. Таким образом, факторный анализ с формальной точки зрения - это, прежде всего, несколько критериев качества матрицы факторных нагрузок и набор алгоритмов поиска экстремумов этих критериев.
Различные критерии формализуют различные содержательные представления о том, что означает хорошее сжатие информации. Поэтому при практическом использовании факторного анализа полезно проведение анализа исходного материала многими методами. Сопоставление результатов дает возможность выделить существенное, общее в проведенных преобразованиях.
В частности, наличие большого сходства между результатами, полученными с помощью различных методов обработки, означает, что сжатое представление исходного материала действительно отражает существо информации, представленной в этом материале, так как практически не зависит от способа формализации.
Факторный анализ тесно связан с другими многомерными статистическими методами, особенно с компонентным анализом (10). Несмотря на внешнее сходство моделей и вычислительных процедур, постановки задач факторного и компонентного анализа существенно различаются.
Компонентный анализ приводит к выделению статистически независимых обобщенных факторов, которые называются главными компонентами. В получаемых компонентах воспроизводится суммарная дисперсия исходных факторов, однако для описания основной доли дисперсии достаточна лишь небольшая их часть. В компонентном анализе осуществляется жесткая процедура выбора главных компонент и исключен субъективный подход.
Исходные переменные преобразуются в новые переменные - главные компоненты, являющиеся линейными комбинациями исходных факторов. Главные компоненты обладают рядом свойств, которые делают их удобными для экономического анализа:
статистическая независимость;
ранжирование по степени их вклада в суммарную дисперсию исходных переменных, что дает возможность выразить информацию, содержащуюся в большом наборе взаимосвязанных исходных переменных, с помощью меньшего числа независимых главных компонент.
Для проведения дальнейшего анализа требуется рассмотреть, насколько тесно каждая переменная в отдельности может быть связана с выделенным набором главных компонент. Исследование ведется на основании так называемых нагрузок, которые фактически являются оценкой тесноты связи исходных переменных и компонент. Именно через эти оценки каждая компонента получает свою содержательную
интерпретацию.
Ограничение применения компонентного анализа связано с более высокими требованиями к точности исходных данных. В случае существенных ошибок измерения исходных данных более оправдано применение факторного анализа, который наряду со сжатием информации позволяет выделить ошибки в характерные факторы и исключить из анализа.
Факторный и компонентный анализы могут использоваться как основной, а также как дополнительный аппарат исследования, позволяющий упростить и сделать более корректным применение других статистических методов.
Переход от множества первоначальных независимых переменных к меньшему числу общих факторов позволяет существенно снизить размерность пространства входных переменных и таким образом решить проблему отбора существенных факторов. Это позволяет производить построение уравнений регрессии и оценку параметров даже при небольших объемах совокупностей.
Зачастую невозможно включить в модель переменные, важные с точки зрения поставленной задачи, из-за отсутствия необходимых данных в действующей отчетности и т.д. Между тем, общие факторы отражают также свойства и переменных, не включенных в анализ, но относящихся к тому же классу, что и переменные, выбранные для исследования.
Общие факторы ортогональны между собой, благодаря чему решается проблема мультиколлинеарности.
Пути построения адекватных моделей. Некоторые решения
Построение адекватных моделей связано с решением следующих задач.
1. Учет многомерности выходного параметра модели.
Существенный недостаток применения корреляционно-регрессионного статистического инструмента исследования при моделировании и прогнозировании инвалидности состоит в том, что игнорируется существенная комплексность механизма формирования инвалидности, выражающаяся в частности во взаимосвязях и взаимообусловленности отдельных показателей инвалидности. Пофакторный подход, когда отдельно устанавливается регрессионная связь каждого из показателей инвалидности со своим набором факторов-детерминант, искусственно разъединяет систему характеристик, описывающих единое явление, на отдельные компоненты, рассматриваемые изолированно от остальных показателей.
Для решения подобных задач была предложена принципиально иная логика использования математико-статистического аппарата, опирающаяся на методы классификации многомерных наблюдений и методы снижения размерности (10).
Многомерная статистика рассматривает совокупность изучаемых многомерных объектов как совокупность точек или векторов в пространстве описывающих их признаков. Каждый объект социальной сферы характеризуется, с одной стороны, некоторым набором факторов-детерминант (например, социально-демографических и других признаков, описывающих условия существования объекта), а с другой - набором параметров поведения.
Решение общей проблемы, связанной с выявлением структуры и дифференциации, распадается в соответствии с принятой в данной работе логической схемой на следующие этапы:
сбор и первичная обработка данных;
выявление основных типов с помощью разбивки исследуемого множества точек-объектов на классы в пространстве признаков, описывающих тип поведения;
отбор наиболее информативных типообразующих признаков (факторов-детерминант). Неправомерно рассчитывать на то, что диапазоны возможных значений каждого из типообразующих признаков окажутся непересекающимися для объектов разных типов потребительского поведения. Естественно считать наиболее информативными те факторы-детерминанты или те их наборы, разница в законах распределения которых оказывается наибольшей при переходе от одного класса к другому.
Эта идея была положена в основу метода отбора наиболее информативных типообразующих признаков.
Отобрав небольшое число наиболее информативных факторов-детерминант, исследуемая совокупность объектов вновь разбивается на классы, но уже в пространстве отобранных типообразующих признаков. При этом результат разбивки существенно зависит не только от состава группы наиболее информативных типообразующих признаков, но и от того, каким образом вычисляется расстояние между двумя точками-объектами в этом пространстве и, в частности, с какими весами участвуют в этом расстоянии отобранные типообразующие признаки. Веса подбирают таким образом, чтобы результат разбивки объектов на классы в пространстве наиболее информативных факторов-детерминант в некотором смысле наименее отличался бы от разбивки тех же объектов, которая получается в пространстве их поведения.
Таким образом находится однозначное соответствие этих структур.
2. Учет неоднородности совокупности (статика).
Анализируя возможность построения моделей с применением корреляционно-регрессионного анализа, мы вновь возвращаемся к сформулированным в предыдущем разделе проблемам адекватности модели.
Важной частью экономико-статистического исследования является анализ однородности сформированной совокупности и выбор наиболее рационального для данных условий типа модели.
Общеизвестно, что статистические закономерности носят усредненный характер и многофакторные регрессионные модели, как правило, дают хорошую аппроксимацию лишь для объектов, близких к средним. Таким образом, регрессионная модель применима к индивидуальному объекту только в однородных совокупностях.
Однородность здесь понимается в смысле справедливости полученных статистических закономерностей формирования социально-экономических показателей для каждой единицы совокупности.
В терминах статистического моделирования достаточная степень однородности будет обеспечена, если многомерное распределение моделируемого показателя и существенно влияющих на него факторов близко к нормальному, иначе говоря, когда статистическая совокупность состоит из одного образа, одного класса, а искажение происходит за счет влияния несущественных с точки зрения цели моделирования факторов и некоторых шумов.
Рассмотрим сферу приложения двух классических подходов к достижению однородности рассматриваемых групп объектов: комбинационных группировок и методов многомерной классификации.
При использовании методов комбинационной группировки классификация осуществляется путем последовательного логического деления совокупности по отдельным признакам. Все элементы сформированных групп обладают одинаковыми значениями комплекса признаков группировки.
Другими словами, достаточным и необходимым условием принадлежности единицы совокупности к данной группе является наличие соответствующих значений комплекса группировочных признаков. В пределах набора признаков группировки элементы групп неразличимы.
В ходе развития научных исследований было установлено, что принципы чистой логики, лежащие в основе метода комбинационной группировки, нелегко применять к эмпирическому материалу. Часто можно обнаружить естественные типы явлений, каждый из которых объединяет индивидуальные явления, обладающие большим числом общих признаков, но никакой естественный тип невозможно выразить через небольшой набор совпадающих признаков.
В некоторых случаях те или иные объекты можно без всяких сомнений отнести к определенному типу, несмотря на отсутствие или несовпадение у них нескольких признаков из числа использованных при формировании групп. Все это обусловило необходимость разработки новых принципов многомерной классификации, отличных от классических, суть которых состоит в том, что классификация объектов производится не последовательно по отдельным, а одновременно по большому числу признаков.
При использовании комбинационной группировки объект, отклоняющийся от нормы, характерной для группы, по одному единственному признаку набора, будет автоматически исключен из группы. Более того, если этот признак используется на первом этапе группировки, то объект может легко попасть в группу, очень далекую от той, с которой он в действительности имеет наибольшее сходство. Таким образом, осуществляя классификацию методом комбинационных группировок, исследователь часто искусственно разрушает реально существующие в пространстве признаков обособленно-однородные классы жестко заданными интервалами признаков.
Этот основной недостаток делает комбинационные группировки неэффективными для выделения типов объектов по комплексу признаков, так как с добавлением каждого нового признака опасность разрушения объективно существующих однородных групп возрастает. Следовательно, основное преимущество методов многомерной классификации заключается в том, что они позволяют с той или иной степенью приближения наметить и выделить реально существующие в признаковом пространстве скопления точек-объектов, что связано с одновременной группировкой по большому числу признаков и использованием в качестве границ сложных поверхностей.
Приведенная краткая характеристика корреляционно - регрессионного анализа и методов многомерной классификации свидетельствует о том, что эти два вида методов эмпирического изучения связей хорошо дополняют друг друга. Комплексное применение обоих методов позволяет существенно расширить сферу приложения методов регрессионного анализа, хотя во многих случаях аппарат многомерной классификации может выступать и как самостоятельный инструмент построения модели социально-экономического процесса. При совместном их применении на первом этапе проводится разбивка совокупности объектов на классы близких точек. В каждом из выделенных классов строится своя функция регрессии.
В отличие от обычной регрессионной функции, параметры которой остаются стабильными для всех объектов совокупности, здесь параметры модели различны для выделенных областей. Сходства и различия полученных моделей для разных типов объектов несут в себе содержательную информацию о характере и степени влияния факторных признаков.
3. Анализ устойчивости зависимостей во времени
Существует два принципиально различных подхода к анализу устойчивости статистических зависимостей во времени. Первый из них сводится к анализу устойчивости характеристик исходной выборки, второй - к анализу устойчивости параметров модели.
Суть первого подхода состоит в проверке идентичности не самих уравнений, а условий, которые обеспечивают эту идентичность. Этим условием является стабильность во времени основных параметров исследуемой совокупности. В качестве критерия стабильности может выступать близость классификации объектов по данным нескольких лет.
Алгоритм реализации этой проверки может выглядеть следующим образом. Если имеются данные о некотором числе объектов, характеризующихся определенным набором признаков за два года, то вначале производится группировка этих объектов независимо от года.
Образуется некоторое число классов - s. Затем производится разбивка на k новых групп - по году. Результаты двойной группировки представляют в виде таблицы взаимной сопряженности номеров групп и числа лет.
По таблице взаимной сопряженности вычисляется значение 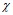 2 - Пирсона и сравнивается с табличным.
2 - Пирсона и сравнивается с табличным.