
Структура трехуровневой активной системы
Приведем ряд необходимых и достаточных условий сообщения достоверной информации как доминантной стратегии. Необходимым и достаточным условием сообщения достоверной информации как доминантной стратегии при любых идеальных точках является существование множеств Xi(s_i), для которых выполнены условия совершенного согласования [137, 169].
Напомним, что Xi(s.i) - множество допустимых планов i-го АЭ, которое в соответствии с условиями приведенного выше результата зависит от сообщений остальных элементов s-i и не зависит от сообщения si i-го АЭ. Рассмотрим механизм с сильными штрафами за отклонение состояния от плана, то есть механизм с полной централизацией планирования [84, 148, 195].
Пусть множество допустимых планов представимо в виде: $ Di(s-i): Xi(s-i) = Xi n Di(s-i) Ф 0. В [137] доказана теорема о том, что для того, чтобы механизм с сильными штрафами обеспечивал сообщение достоверной информации как доминантной стратегии при любых точках пика, необходимо и достаточно, чтобы: 1) существовали множества Di(s-i); 2) выполнялись условия совершенного согласования. Соответствующие вычислительные процедуры рассматривались в [136, 138, 145, 318].
Интересным и перспективным представляется предложенный в [240] геометрический подход к получению достаточных условий неманипулируемости путем анализа конфигураций множеств диктаторства. В рамках этого подхода уже удалось получить ряд конструктивных условий индивидуальной и коалиционной неманипулируемости механизмов планирования в АС.
Достоверность сообщаемой информации при использовании принципа ОУ при условии, что множество допустимых планов АЭ не зависит от сообщаемой им оценки, интуитивно обосновывает рассмотрение систем с большим числом элементов. Пусть часть плановых показателей 1 является общей для всех элементов, то есть номенклатура плана имеет вид p = (1, {xJ). Если искать управления 1, выгодные для всех элементов системы (как это делается при использовании принципа согласованного планирования), то возникает принципиальный вопрос о существовании решения.
Такого рода проблем не возникает в системах с большим числом элементов, когда влияние оценки отдельного элемента на общее управление мало. Если при сообщении своей оценки у- каждый АЭ не учитывает ее влияния на 1(s), то считается выполненной гипотеза слабого влияния (ГСВ).
При справедливости ГСВ необходимо согласовывать планы только по индивидуальным переменным. В [84, 123, 137] доказано, что если выполнена ГСВ и компоненты x(s) плана удовлетворяют условиям совершенного согласования, то сообщение достоверной информации является доминантной стратегией.
В [84, 242] приведены условия выполнения гипотезы слабого влияния и для ряда примеров показано, что при достаточно большом числе элементов в системе это условие выполняется.
До сих пор мы интересовались, в основном, условиями сообщения достоверной информации. Возникает закономерный вопрос: как соотносятся такие свойства механизма
функционирования как неманипулируемость и оптимальность? Иначе говоря, всегда ли среди оптимальных механизмов найдется неманипулируемый и, соответственно, всегда ли среди неманипулируемых механизмов содержится хоть один оптимальный.
Получить ответ на этот вопрос необходимо, так как, быть может, не обязательно стремиться к обеспечению достоверности информации, лишь бы механизм имел максимальную эффективность. Поэтому приведем ряд результатов по оптимальности (в смысле максимальной эффективности) механизмов открытого управления (см. также условия неманипулируемости ^согласованных механизмов в [195]).
Известно [142, 155], что в АС с одним активным элементом для любого механизма существует механизм открытого управления не меньшей эффективности.
Для систем с большим числом элементов результат об оптимальности механизмов открытого управления справедлив лишь для ряда частных случаев. Например, аналогичные результаты были получены для механизмов распределения ресурса [123, 194, 243] и для механизмов выработки коллективных экспертных решений (задач активной экспертизы) [123, 155] (см. также ниже описание базовых механизмов ТАС).
Более общие, но достаточно громоздкие достаточные условия неманипулируемости, обобщающие результаты по механизмам распределения ресурса и механизмам активной экспертизы, приведены в [375, 376].
Если в рамках ГСВ ввести дополнительное предположение, что план x(s) может быть представлен в виде функции от общего управления l(s) и сообщения si, то при Xi =Xi(s_i) на множестве таких механизмов существует оптимальный механизм ОУ [123, 243, 315] (см. также выше). Оптимальность механизма ОУ имеет место также на множестве механизмов с сильными штрафами. Анализ законов ОУ в задачах распределения ресурса проведен в [242].
В этой работе также вводится ряд условий на законы управления (названные законами минимально разумного управления), обеспечивающих асимптотически оптимальное распределение ресурса в точке равновесия Нэша с ростом числа элементов.
Полученные в ТАС результаты о связи оптимальности и неманипулируемости механизмов вселяют некоторый оптимизм, в том смысле, что эти два свойства не являются взаимно исключающими. В то же время ряд примеров (см., например, [84, 153, 233, 240, 376]), свидетельствуют о неоптимальности в общем случае механизмов, обеспечивающих сообщение элементами достоверной информации.
Вопрос о соотношении оптимальности и неманипулируемости в общем случае остается открытым.
Неманипулируемость механизма функционирования является одним из основных его свойств, изучаемых в теории коллективного выбора. Сравнительный обзор основных результатов, полученных отечественными и зарубежными авторами в этой области, приведен в [153].
Выше при рассмотрении механизмов стимулирования в АС согласованными были названы механизмы, побуждающие АЭ к выполнению планов. В АС, в которых стратегией АЭ является как выбор сообщений, так и действий (комбинация задач стимулирования и планирования - см. формальное описание в [195]), механизмы, являющиеся одновременно согласованными и неманипулируемыми, получили название правильных. Значительный интерес представляет вопрос о том, в каких случаях оптимальный механизм можно искать в классе правильных механизмов.
Ряд достаточных условий оптимальности правильных механизмов управления АС приведен в [149, 195, 376, 382]. Также следует отметить результаты исследования механизмов критериального управления [84, 323, 342, 346], при использовании которых центр выбирает целевую функцию АЭ из заданного класса.
6. Расширения базовой модели
Под расширениями базовой модели управления активными системами понимаются рассматриваемые ниже динамические активные системы (функционирующие в течение нескольких периодов времени), многоуровневые активные системы и активные системы, функционирующие в условиях неопределенности (см. классификацию задач управления АС выше).
6.1. Динамические активные системы
Интуитивно понятно, что при таком естественном обобщении простейшей базовой (статической) модели, как рассмотрение нескольких несвязанных периодов функционирования, задачу управления удается декомпозировать, развалив ее на набор базовых. Трудности появляются при исследовании систем со связанными периодами функционирования. Методы и алгоритмы решения задачи синтеза оптимального механизма управления в этом случае характеризуются высокой структурной и вычислительной сложностью. Как правило, универсального подхода к аналитическому решению этого класса задач найти не удается.
Однако, преодоление трудностей анализа оправданно, так как в динамических АС присутствуют новые качественные свойства, отсутствующие в базовой модели (не говоря уже о том, что большинство реальных организационных систем функционируют достаточно долго).
Динамические АС, функционирующие в течение длительного времени, существенно отличаются от статических: возможность адаптации, сглаживания влияния случайных параметров на результаты деятельности АЭ, пересмотра стратегий - все эти эффекты появляются при переходе от статических к динамическим АС. Основными характеристиками динамических моделей являются степень учета игроками будущего и конечность или бесконечность игры. Модели, учитывающие дальновидность АЭ - способность спрогнозировать будущие последствия принимаемых сегодня решений, гораздо труднее поддаются анализу, нежели чем модели с недальновидными АЭ, но, в то же время, являются более адекватными действительности.
В бесконечных играх (бесконечное повторение одношаговых игр) центр имеет больше возможностей по управлению элементами, в отличие от конечных игр, в которых в последние периоды АЭ может, не опасаясь будущего наказания, делать что ему заблагорассудится [276, 371]. Отметим, что используемые здесь и далее термины конечная и бесконечная (игра) характеризуют не множества допустимых стратегий АЭ, а число периодов функционирования АС.
Содержательно, качественное отличие повторяющихся (многопериодных) игр от обычных (статических, однопериодных) заключается в том, что наличие нескольких периодов повышает ответственность игроков за свои действия - если кто-то повел себя не так как следовало, то в следующих периодах он может быть наказан остальными игроками за это отклонение. Для того, чтобы
предотвращать отклонения, наказание должно быть достаточно сильным и компенсировать возможный выигрыш игрока, который тот получает отклоняясь. Переключение с нормального режима на наказание (и быть может возвращение к исходному режиму через несколько периодов) получило название триггерной стратегии.
Примеры того, как строить триггерные стратегии и того, как определить наилучший момент переключения (ведь не всегда можно достоверно установить факт отклонения), приведены в [371].
Существенной в повторяющихся играх оказывается информированность игроков. Если все игроки наблюдают все стратегии, выбранные партнерами в прошлом, то говорят, что имеет место полная информированность [371]. Если же стратегии, выбираемые в прошлом, ненаблюдаемы, а есть другая информация, например, если наблюдаемы полезности игроков, то имеет место неполная информированность.
При полной информированности в суперигре (последовательности однопериодных игр) может существовать равновесие Нэша, доминирующее по Парето равновесие Нэша однопериодной игры. Если игроки не дисконтируют будущие полезности, то множества равновесных векторов полезностей в однопериодной и многопериодной игре совпадают.
Если игроки дисконтируют будущие полезности, то все равновесия суперигры, в принципе, могут быть неэффективны (по Парето), хотя, обычно, при условии, что дисконтирующие множители не очень малы, существуют равновесия суперигры, доминирующие по Парето однопериодные [276, 336, 371].
В теории активных систем исследование динамики функционирования проводилось, в основном, для следующей модели [31, 410, 425]. В активной системе, состоящей из центра и одного АЭ, целевая функция центра в периоде t имеет вид Ft(xt,yt), а активного элемента: ft(xt,y), xt - план на период t, yt - действие, выбранное АЭ в этом периоде. Траектория x = (x1t x2, , xT) называется плановой траекторией, а траектория y = (y1t y2, , yT) -траекторией реализаций.
Как и в одноэлементной статической задаче, центр выбирает систему стимулирования и устанавливает планы (на каждый период), а АЭ выбирает действие, максимизирующее его целевую функцию. Возникает вопрос - что понимать под целевой функцией АЭ в этой повторяющейся игре.
Если допустимые множества не изменяются со временем и АЭ вообще не учитывает будущего (недальновидный АЭ), то задача сводится к набору статических задач.
Достаточно детально в ТАС были изучены так называемые активные системы с динамикой модели ограничений [32, 40, 195, 414, 416]. Изменение модели ограничений (допустимых множеств) со временем учитывается зависимостью множества допустимых действий АЭ в периоде t от его действий в предыдущем периоде и от плана текущего периода, то есть At = At(xt, yt-1), t = 2,T, A1 = Aj(xj).
Таким образом, при известной плановой траектории недальновидный АЭ будет решать задачу поиска траектории реализаций: ft(xt,y)® max , t = 2,T. Целевая функция
yt eAt(xt,yt-i) I дальновидного АЭ имеет вид: gt = ft(xt,y) + X d k fk(xk,yk), где d - k=t+1
коэффициент дисконтирования. Для верхнего индекса суммирования возможны следующие варианты: I = t + N (фиксированный горизонт) - АЭ учитывает N будущих периодов, I = T - АЭ учитывает все будущие периоды и т.д. [425, 426, 432].
То есть дальновидный АЭ в каждом периоде t решает задачу выбора реализаций (действий - yt, yt+1, ) с целью максимизации gt. Задача центра заключается в выборе плановой траектории, т максимизирующей его целевую функцию, имеющую вид: X d t
t=i
Ft(xt,yt), считая, что реализации будут совпадать с планами. Если АЭ и центр имеют различные степени дальновидности (N + 1 T), то АЭ не может построить прогноз на весь плановый период.
В работах [425, 426] приведены условия на распределения дальновидностей, обеспечивающие совпадение реализации с планом, и показано, что динамическую задачу удается свести к статической, решаемой в расширенном пространстве параметров.
При решении задачи планирования центр может предполагать, что реализации совпадут с планами. Известно, что достаточным условием согласованности системы стимулирования в статической АС является, например, выполнение неравенства треугольника для функций штрафов. Для согласованности в динамической модели достаточно выполнения неравенства треугольника для взвешенных сумм штрафов.
Если в течение нескольких периодов штрафы не являются согласованными, то для согласования в динамике достаточно существования сильных штрафов в будущем [426].
Рассмотренная выше модель ограничений зависела от параметров, выбираемых участниками системы. Однако возможны случаи, когда допустимые множества зависят от случайных параметров (или когда, как в повторяющихся играх при неполной информированности, не все выбираемые стратегии наблюдаемы).
Следовательно, возникает задача идентификации, решаемая при использовании адаптивных механизмов функционирования [31-39, 104, 263, 266-268, 407-416].
Суть механизмов адаптивной идентификации заключается в использовании центром информации о планах, реализациях и т.д. дальновидного АЭ для оценки параметров его модели ограничений, прогноза состояний, поощрения и т.д. Пусть множество возможных действий зависит от неизвестного центру потенциала АЭ, а потенциал, в свою очередь, зависит от управления со стороны центра и некоторой случайной величины. На основании наблюдаемой реализации центр может определить оценку потенциала с помощью той или иной рекуррентной процедуры прогнозирования [410].
Примером решения задачи адаптивного планирования может служить модель динамического простого АЭ, подробно описанная в [84].
При исследовании адаптивных механизмов возникают задачи выбора наилучшей процедуры прогнозирования; синтеза механизма, при котором АЭ полностью использует свой потенциал (такие механизмы получили название прогрессивных [408, 410, 413]); определения реальности плановых траекторий; синтеза оптимального механизма управления и т.д.
Основной вопрос, возникающий при изучении динамических контрактов (подкласса моделей стимулирования), заключается в выяснении преимуществ, которыми обладает динамический контракт со связанными периодами и памятью (в контракте с памятью вознаграждение в текущем периоде зависит от результатов текущего и предыдущих периодов), по сравнению с последовательностью обычных однопериодных контрактов. Обычно в моделях рыночной экономики предполагается, что если число АЭ велико, то игра некооперативная, а если мал'о, то -кооперативная.
В динамических моделях возможность кооперации появляется именно из-за динамики - элементы имеют время договориться и наказать тех, кто отклоняется от соглашений [371].
Решение однопериодной задачи - равновесные по Нэшу платежи (значения целевых функции центра и АЭ), как правило, неэффективны и доминируются по Парето другими платежами. Следовательно, в последовательности однопериодных контрактов (игр) средние платежи равны равновесным по Нэшу, а в динамическом контракте они могут достигать или приближаться к Парето оптимальным значениям (см. также выше).
Обычно результаты об оптимальности (достижимости Парето-решения) требуют бесконечного повторения однопериодных игр, а для конечного числа периодов доказывается е-оптимальность. При отсутствии дисконтирования любое индивидуально-рациональное распределение выигрышей в однопериодной игре является достижимым и Парето оптимальным распределением выигрышей в суперигре [276, 371].
В то же время, если в однопериодном контракте центр может достаточно сильно наказывать АЭ (соответствующие условия на ограничения механизма стимулирования приведены в [234, 371]), то последовательное заключение краткосрочных контрактов оказывается не менее эффективно, чем заключение долгосрочного контракта. Иными словами, если долгосрочный контракт реализует некоторую последовательность действий, то при достаточно сильных штрафах, существует оптимальная последовательность краткосрочных контрактов, реализующая ту же последовательность и дающая всем участникам те же значения ожидаемой полезности.
Содержательно, возможная сила штрафов должна быть такова, чтобы за их счет достаточно сильно наказать АЭ за отклонение именно в однопериодном контракте (в динамике эту роль играют стратегии наказания, используемые в следующих периодах).
6.2. Многоуровневые активные системы
С одной стороны, во многих основополагающих работах по теории управления организациями подчеркивается необходимость исследования именно иерархических АС, а с другой стороны подавляющее большинство исследований формальных моделей ограничивалось двухуровневыми расширениями базовой модели. Исключениями для ТАС являются следующие перечисляемые ниже работы.
Исторически, в теории активных систем неоднократно производились попытки обобщения результатов исследования двухуровневых моделей на случай многоуровневых систем, однако в итоге дело, к сожалению, ограничивалось лишь качественным обсуждением или формулировкой частных задач [84, 87, 147, 195, 242, 329]. В теории иерархических игр рассматривались задачи точного агрегирования, задачи с двумя управляющими органами и модели кооперации (образования коалиций между элементами нижнего и промежуточного уровней) в трехуровневой системе [276, 279, 336].
Одной из первых попыток относительно систематического изучения многоуровневых АС явилась монография [363].
Рассмотрим трехуровневую активную систему, состоящую из одного центра - на верхнем уровне иерархии, n промежуточных центров {Ц} на втором уровне, j=1,n, и N управляемых объектов -
_ _ n активных элементов {АЭ^}, i =1,nj, j=1,n, ^nj = N, на нижнем j=1 уровне (см. рис.2).
Будем считать, что каждый АЭ подчинен одному и только одному центру промежуточного уровня, то есть структура подчиненности в рассматриваемой АС имеет вид дерева. Совокупность центра Ці промежуточного уровня и nj подчиненных ему АЭ называют j-ой подсистемой, совокупность центра и промежуточных центров называют метасистемой.
Было установлено, что влияние изменения централизации (то есть централизация или децентрализация АС) на эффективность управления вызвано действием следующих, присущих многоуровневым системам, факторов.
Фактор агрегирования (А) заключается в изменении информированности участников системы в результате агрегирования информации о состояниях и поведении конкретных АЭ, подсистем и т.д. по мере роста уровня иерархии.
Метасистема
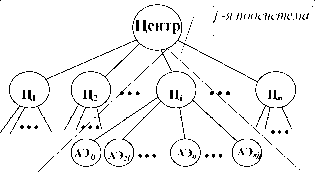
Рис.2. Структура трехуровневой активной системы веерного типа
Экономический фактор (Э) заключается в изменении ресурсов управления (ограничений механизмов управления, множеств допустимых стратегий и т.д.) при введении новых участников (АЭ, промежуточных управляющих органов и т.д.), обладающих собственными интересами, то есть участников, либо привносящих новые ресурсы управления, либо потребляющих часть имеющихся ресурсов.
Фактор неопределенности (Н) заключается в изменении информированности участников АС о существенных внутренних и внешних параметрах их функционирования (в том числе - в изменении неопределенности в субъективных оценках ситуации) в результате изменения состава системы, ее структуры (информационных и других связей между участниками АС) и т.д.
Организационный фактор (О) заключается в изменении отношения власти, то есть возможности влияния на деятельность элементов системы. В частности, власть как система поощрений и штрафов позволяет добиться преобладания коллективного интереса над индивидуальными целями.
Информационный фактор (И) заключается в изменении информационной нагрузки на участников АС и вызван, в первую очередь, объективной ограниченностью их способностей по передаче и переработке информации.
Строки таблицы содержат факторы, которые оказывают влияние, столбцы - факторы, на которые оказывается влияние. Если на пересечении i-ой строки и j-го столбца стоит символ , то i-ый фактор не оказывает непосредственного влияния на j-ый, если стоит символ - , то - оказывает.
В работе [363] получены достаточные условия идеального агрегирования в задачах стимулирования в трехуровневых АС, а также доказана произвольная децентрализуемомъ анонимных механизмов распределения ресурса, механизмов экспертизы, механизмов внутренних цен, а также некоторых механизмов страхования.
Возможные нарушения принципа единоначалия, то есть рассмотрение АС, в которых АЭ подчинен одновременно нескольким центрам, изучались при исследовании АС с распределенных контролем [363, 406]. Этот класс АС требует дальнейших систематических исследований.
6.3. Активные системы, функционирующие в условиях неопределенности
В соответствии с введенной выше классификацией АС, функционирующие в условиях неопределенности могут быть классифицированы по: информированности участников
(симметричная - С, асимметричная - А), типу неопределенности (внутренняя и внешняя) и виду неопределенности (интервальная, базовая и нечеткая). Перечисляя все возможные комбинации значений признаков классификации по этим основаниям, получаем двенадцать базовых моделей АС с неопределенностью, которые, совместно с базовой детерминированной моделью условно обозначим М1 - М13.
Таблица 2 содержит описание этих базовых моделей, а также указание на те разделы теории управления, в которых они исследовались (ТК - теория контрактов, ИТИС -информационная теория иерархических систем, ТР - теория реализуемости) и ссылки на основные работы, содержащие результаты изучения соответствующих моделей. Следует подчеркнуть, что в изучении АС с нечеткой неопределенностью ТАС обладает абсолютным приоритетом.
Приводимые в [382] результаты систематического исследования базовых задач стимулирования в АС с неопределенностью свидетельствуют, что в рамках базовых моделей (одноэлементных, статических) механизмов (задач) стимулирования возможен единый методологический подход (исходный принцип, охватывающий всю совокупность используемых методов) к решению задач анализа и синтеза систем стимулирования. Несмотря на многообразие изучаемых моделей, используемый подход заключается в единообразии их описания, общности технологии (совокупности методов, операций, приемов, этапов и т.д., последовательное осуществление которых обеспечивает решение поставленной задачи), и техники (совокупность навыков, приемов, умений, позволяющая реализовывать технологию) исследования, причем последняя основывается, как и детерминированная теория, на изучении множеств реализуемых действий и минимальных затрат на стимулирование.
Поясним последнее утверждение, обобщив описание, технологию и технику построения и исследования моделей механизмов стимулирования как в детерминированных активных системах, так и в АС с различными типами и видами неопределенности.
После описания модели, то есть задания в соответствии с введенными выше параметрами модели и системой классификаций задач управления в АС класса исследуемых активных систем, определяется рациональное поведение АЭ: на основании известных предпочтений АЭ на множестве результатов деятельности (эти предпочтения зависят от используемого центром механизма управления) и имеющейся информации о неопределенных факторах (взаимосвязи между действиями АЭ и результатами его деятельности) определяются предпочтения АЭ на множестве его стратегий (действий и/или сообщаемых оценок). В случае интервальной неопределенности этот переход осуществляется с использованием принципа МГР, в случае вероятностной (нечеткой) неопределенности целевая функция АЭ на множестве результатов его деятельности совместно с распределением вероятностей (нечеткой информационной функцией) индуцирует на множестве допустимых стратегий целевую функцию - ожидаемую полезность (индуцированное нечеткое отношение предпочтения (НОП) и т.д.). Множество выбора (решений игры) при заданном множестве стратегий и предпочтениях АЭ, выражаемых, например, его целевой функцией, НОП и т.д., определяется стандартным образом. В случае, если множество выбора состоит более, чем из одного элемента, необходимо доопределить однозначно (используя ГБ или МГР) выбор АЭ.
Этот выбор будет зависеть от механизма управления, эффективность которого задается значением целевой функции центра на множестве выбора АЭ (если предпочтения центра зависят от неопределенных параметров, то необходимо найти его детерминированную индуцированную систему предпочтений). Следует отметить, что структура предпочтений центра и АЭ (возможность ранжирования стратегий) в большинстве случаев позволяет определять выбор (недоминируемые стратегии) достаточно тривиально.