
ГА+ИНС = НОВАЯ ПАРАДИГМА В МОДЕЛИРОВАНИИ
Тем более, что представленные примеры вроде бы свидетельствуют в пользу этого довода. Однако это не так, и в следующем разделе мы продемонстрируем, что эти же две технологии способны самостоятельно синтезировать математическую модель динамического объекта только на основании знания его переходных характеристик.
ГА+ИНС = НОВАЯ ПАРАДИГМА В МОДЕЛИРОВАНИИ
Физика представляет собой развивающуюся логическую систему мышления, основы которой можно получить не выделением их какими-либо индуктивными методами из пережитых опытов, а лишь свободным вымыслом. Обоснование (истинность) системы основано на доказательстве применимости вытекающих из нее теорем в области чувственного опыта, причем соотношения между последними и первыми можно понять лишь интуитивно.
Эволюция происходит в направлении все увеличивающейся простоты логических основ. Больше того, чтобы приблизиться к этой цели, мы должны решиться признать, что логическая основа все больше и больше удаляется от данных опыта, и мысленный путь от основ к вытекающим из них теоремам, коррелирующим с чувственными опытами, становится все более трудным и длинным.
А. Эйнштейн. Физика и реальность.
Нейронные сети и дифференциальные уравнения относятся к различным ветвям в моделировании, известным как эмпиризм и фундаментализм. Первая ветвь, эмпиризм, восходит к работам Аристотеля и Леонардо да Винчи, вторая, фундаментализм, обязана своим рождением Галилею, пытавшемуся реализовать в моделировании теологические представления Платона о мире идей и учение о душе. Дифференциальные уравнения описывают душу объекта, в то время как нейронная сеть оказывается в состоянии запомнить, а потом воспроизвести динамическое поведение объекта в ситуациях, которые ей известны.
Аналитическая форма представления знаний ей недоступна, она способна запомнить и обобщить только конкретные эмпирические зависимости, хотя речь здесь идет, конечно, не о запоминании данных в табличном виде.
Для классической парадигмы характерно то, что синтезу математической модели объекта или процесса обязательно предшествует фаза анализа, в течение которой процесс умозрительно декомпозируется на элементарные явления, каждое из которых подвергается затем тщательному исследованию. Сначала всегда планируется очищенный эксперимент, в котором исследуемая составляющая процесса обособляется от влияния остальных, а затем, по мере реальных возможностей, этот эксперимент выполняется. Как результат, выдвигается предельно простая, обыкновенно линейная, модель явления с единственным постоянным коэффициентом, для которого либо из условий проведения эксперимента, либо из каких-то третьих условий подбирается прозрачная физическая интерпретация. Если какую-то составляющую в чистом виде изучить не удается, на нее нередко просто закрывают глаза.
Наконец, осуществляют синтез полной модели, складывая из частных линейных моделей как из кирпичиков цельную картину процесса, правда, с оговоркой, что коэффициенты, в действительности, могут быть нелинейными.
Примеров таких процедур можно привести множество, мы же предлагаем ограничиться одним предельно простым разрядом батареи конденсаторов на катушку с воздушным сердечником.
Как известно, процесс разряда описывается дифференциальным уравнением
Хотя цепь собрана всего из двух узлов батареи и катушки, членов в уравнении мы видим три. Все они содержат постоянные коэффициенты.
Коэффициент при токе R, известный как активное сопротивление катушки, представляет собой не что иное, как коэффициент пропорциональности между напряжением на катушке и током, при условии того, конечно, что катушка запитана от источника постоянного напряжения (очищенный эксперимент 1). Коэффициент при производной тока L собственная индуктивность катушки имеет отношение к другому эксперименту: если запитать катушку от источника гармонически изменяющегося напряжения достаточно высокой частоты (очищенный эксперимент 2), то произведение круговой частоты колебаний и собственной индуктивности катушки опять даст нам коэффициент пропорциональности между амплитудами тока и напряжения на зажимах катушки.
Наконец, емкость конденсатора C тоже нуждается в определении и появляется она как понятие, опять-таки, из какого-то очищенного эксперимента 3, вскрывающего связь тока и напряжения на обкладках конденсатора.
Стоит задуматься, насколько натянуты предположения в отношении постоянства всех этих коэффициентов. Мы закрыли глаза на внутренние тепловыделения в проводнике, условия охлаждения катушки, потери в диэлектрике конденсатора.
Перечень неучтенных факторов расширится, если мы возьмем катушку с железным сердечником, который не только сможет влиять на индуктивность, но и откроет дополнительные возможности для увеличения тепловых потерь в системе (от вихревых токов, на перемагничивание ит. д.).
Ничего этого в модели (10) нет. Всякий раз, чтобы учесть тот или иной фактор, нам придется конструировать новый эксперимент, предлагать модель явления, определять и интерпретировать ее параметры.
При отсутствии модели мы не сможем описать эффект, следовательно, шаблон уравнения, описывающего процесс, будет заведомо неполным.
Тем не менее, никто не мешает нам выполнить идентификацию той модели, которая у нас есть. Правда, для этого нам все равно придется выполнить эксперименты со всей цепью, после чего подобрать значения коэффициентов так, чтобы погрешность предсказания поведения тока была минимальной. Не важно, насколько точно найденные значения коэффициентов совпадут с теми, что получились бы из частичных исследований. Мы и не можем ожидать, что они совпадут члены, присутствующие в шаблоне, должны взять на себя вклад отсутствующих.
Как следствие, значения коэффициентов получат некоторые приращения, зависящие, по-видимому, еще и от того, например, в каком диапазоне токов проводились эксперименты со всей цепью. Ясно, что идентифицированная модель будет достоверна только в этом диапазоне, но вряд ли мы можем надеяться, что при других токах параметры модели останутся прежними.
В чем же состоят отличия нейросетевого подхода? Да, пожалуй, только в том, что он изначально не подразумевает фазы анализа при построении модели. Нейронные сети это существенно синтетический, а не аналитический подход. Конечно, и здесь остается понятие шаблона, и здесь синтез модели сводится к параметрической оптимизации шаблона, сконструированного по базису активационных функций нейронов.
Но здесь никого не интересует, какому гипотетическому поведению объекта соответствует активность одного из нейронов и какой физический смысл приобретают в этом случае синаптические веса. Задача формулируется для всей сети в целом.
Исходя из этого и объект исследуется сразу целиком, и не в очищенных ситуациях, а в тех режимах, которые нас интересуют в практическом, утилитарном отношении.
Хотя мы можем предположить, что нейронная сеть может выполнить сколь угодно сложное преобразование вход-выход, заранее невозможно предсказать, какая архитектура сети (то есть вид шаблона) окажется наилучшей для решения интересующей нас задачи. Какой вид активационных функций нейронов должен быть выбран? Какая слойность сети и сколько нейронов в каждом скрытом слое обеспечат требуемую информационную емкость сети?
Не очевиден и вопрос о количестве обратных связей, охватывающих сеть, а ведь без них поведение сети не сможет стать динамичным.
Как бы ни было, численное экспериментирование является на сегодняшний день единственным надежным методом поиска ответов на поставленные вопросы.
Следует отметить, что нейросетевые модели, все-таки, сильно отличаются от того, что обычно понимают под математической моделью. Не зря поэтому их называют эмуляторами, они имитируют динамические характеристики объекта и не более того. Существует для них и другое название предикторы (от английского глагола to predict предсказывать) и оно тоже не беспочвенно, так как нейросетевые модели ориентированы на то, чтобы уметь по текущему и нескольким предыдущим векторам состояния объекта предсказывать его следующие состояния.
В зависимости от глубины предсказания различают одношаговые и краткосрочные предикторы.
Основное отличие между ними состоит в том, что одношаговый предиктор (см. рис. 20,а) получает информацию о текущем состоянии объекта от самого объекта, то есть он жестко привязан к объекту.
Поскольку при таком подходе ошибка в предсказании возникает только в пределах текущего шага, а не накапливается даже на двух ближайших шагах, это существенно понижает требование к точности предсказания, чем и упрощает задачу синтеза.
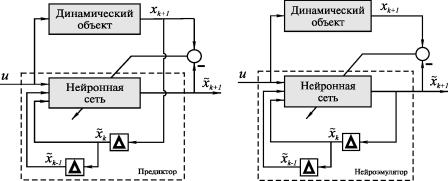
Значительно больших усилий требует синтез так называемого краткосрочного предиктора (см. рис. 20,б), который может предсказывать поведение объекта на 1001000 шагов и который отталкивается в прогнозе каждого последующего шага от собственного прогноза предыдущего шага.
Ясно, что даже если ошибка предсказания на одном шаге выглядит скромно, за 100 шагов она может возрасти до такого предела, за которым теряется какое-либо сходство в поведении эмулятора с поведением объекта в тех же условиях.
Сохраняя верность выбранному принципу действовать в рамках эволюционной парадигмы ее собственными средствами, мы подошли к проблеме синтеза нейросетевых моделей динамических объектов, вооружившись хорошо зарекомендовавшим себя в наших глазах сочетанием ГА+ИНС. Чтобы сохранить некую преемственность с ранее полученными результатами, мы сохранили в качестве динамического объекта инерционное звено второго порядка с теми же значениями коэффициентов, что и в разделе с нейроконтроллером.
Наш первый опыт [25], наверное, и нельзя назвать эмулятором. По существу, мы пытались построить нейронную сеть, которая аппроксимировала бы правые части системы уравнений (9). Для определенности мы приняли, что сеть будет трехслойной с конфигурацией 3-8-2 (т. е. с тремя нейронами во входном слое, восемью нейронами в скрытом слое и двумя суммирующими нейронами в выходном слое). На вход сети подавался входной сигнал и, выходной сигнал на предыдущем шаге х1 и его производная х2.
На выходе сети формировались первая и вторая производная выходного сигнала Х1 и Х2 (см. рис. 21).
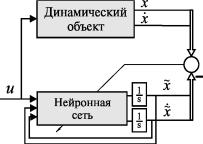
Рис. 21. Первый опыт синтеза эмулятора
n
(11)
X wixi + w0
I i=i
которая являлась неким гибридом сигмоидальной и радиально-симметричной функций.
Основанная на слепом ГА тренировочная процедура включала в себя практически те же этапы, что и при синтезе нейроконтроллера. Популяция состояла из 100 бинарных хромосом.
Каждая хромосома содержала 250 генов и кодировала 50 параметров сети. Пригодность каждого из вариантов сети имитировать реакцию объекта на возбуждение оценивалась путем подачи на вход сети последовательно двух сигналов: единичной ступеньки, а также нулевого сигнала.
Проинтегрированные сигналы с эффектор-ного слоя ИНС сравнивались с результатами решения дифференциального уравнения (9) для тех же случаев. Погрешность работы ИНС оценивалась путем интегрирования ошибок (4) для обоих случаев на интервале времени [0, 10 с] и последующего их суммирования.
Рис. 22 иллюстрирует результаты эмуляции отклика сетью, достигнутые к 5000-му поколению.
Недостатком эмулятора было то, что он хорошо вел себя только при тех возбуждениях, при которых производилось обучение. При подаче на его вход сигнала с промежуточной амплитудой (между 0 и 1) его поведение существенно отличалось от поведения объекта.
Конечно, можно было бы, оставаясь в рамках прежней идеологии обучения, заставить его запомнить поведение объекта при любых значениях амплитуды, но этот путь показался нам слишком экстенсивным. Поэтому мы обратились к методике обучения RBF-сети, представленной на странице 38, и рассмотрели ее как потенциального претендента на роль локального ускорителя ГА.
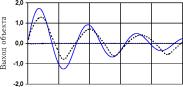
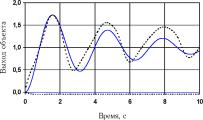
Рис. 22. Переходная функция объекта управления по координатам хг (а) и х2 (б) (сплошная кривая) и ее эмуляция сетью (пунктир)
Сама по себе, методика хороша тем, что позволяет очень быстро решить задачу тренировки сети хотя бы в первом приближении. Вместе с тем, ее ограниченность также бросается в глаза.
Во-первых, она требует большого количества что называется ручного труда, даже если пространство входных сигналов обладает низкой размерностью, а количество входных шаблонов мало. Все равно, мы должны проанализировать, насколько далеко шаблоны расположены друг от друга, чтобы не ошибиться с выбором ширины окон активационных функций.
Во-вторых, ситуация становится обескураживающей, если шаблонов у нас слишком много (скажем, более 1000 или 10000). На практике очень трудно сказать apriori, какие именно эпизоды взаимодействия с объектом могут стать источником хороших шаблонов для построения нейросетевой модели объекта.
Ясно только одно - ситуация, когда мы знаем об объекте мало, заведомо хуже, чем когда мы знаем много.
Конечно, работать с сетью, содержащей 10000 нейронов в скрытом слое, можно, но вряд ли удобно. Да и трудно рассчитывать на быстрое решение уравнения (7). Возникает вопрос а действительно ли нужны все эти шаблоны? Может быть, среди них есть такие, которые достаточно полно характеризуют объект и с которыми только и стоит работать?
Но как тогда их отфильтровать? Можно просто отказаться от части шаблонов, чтобы размеры сети стали удобоваримыми, но тогда мы рискуем потерять важную информацию об объекте и получить некоторое весьма неточное решение поставленной задачи.
Для того, чтобы выяснить, какие шаблоны являются действительно ключевыми в понимании динамики объекта, а также одновременно выполнить синтез нейроэмулятора с минимальной структурой скрытого слоя, мы скомбинировали методику настройки синаптических весов RBF-сети с ГА.
В разработанной процедуре [26,27] на каждой итерации поиска ГА самостоятельно выбирает, в каких точках пространства входных сигналов сети разместить центры активационных функций нейронов скрытого слоя, и назначает для каждой из них ширину окна. Соответственно, в отличие от предыдущего случая слепого поиска, хромосомы содержат теперь только информацию о параметрах нейронов скрытого слоя сети, но не о синаптических весах нейронов выходного слоя.
Схема кодировки хромосом представлена на рис. 23.
| Бинарная строка | ||||||||||||||||||||||
|

При декодировании хромосомы в вектор переменных одновременно с величиной настроечных параметров конкретизируется сама структура скрытого слоя сети.
Из рис. 23 видно, что максимальный размер скрытого слоя ограничен количеством однотипных сегментов, образующих хромосому. В действительности же, в силу того, что мы вынуждены контролировать величину настроечных параметров, он всегда получается несколько меньшим.
На первом этапе проверяется ширина окна активационных функций нейронов. Если для какого-либо из них она оказывается меньше некоторого порогового значения (принятого в наших экспериментах равным 0,01), то такой нейрон опускается.
Кроме того, чтобы можно было воспользоваться методикой настройки синаптических весов, представленной на странице 38, необходимо, чтобы центры активационных функций совпадали с тренировочными шаблонами в пространстве входных сигналов сети. Поэтому мы ввели понятие 8-окрестности вокруг каждого тренировочного шаблона, равную 0,1. Если центр, закодированный в текущем сегменте хромосомы, входит в одну из таких окрестностей, то при дальнейшей настройке сети используется соответствующий тренировочный шаблон. В противном случае вся информация, хранящаяся в текущем сегменте, игнорируется, и вакансия в скрытом слое, зарезервированная для нейрона с тем же номером, остается открытой.
Для сети, сформированной в результате анализа вектора настроечных параметров скрытого слоя, вычисляются по (7) (а не подбираются, как при слепом поиске) синаптические веса выходных нейронов.
Репрезентативность задействованных в обучении сети шаблонов, то есть их способность замещать собой весь имеющийся опыт взаимодействия с объектом, оценивается путем предъявления сети всех известных шаблонов и суммированием ошибки в эмуляции по всему предъявленному набору. Последняя, как и раньше, используется при ранжировании популяции потенциальных решений, отборе особей на элиминирование и в родительскую группу для последующего скрещивания.
Алгоритм процедуры синтеза представлен на рис. 24.
Для проверки методики мы воспользовались предыдущей тестовой задачей. Сначала заменили объект библиотекой тренировочных шаблонов, сгенерировав ее посредством решения системы уравнений (9) при различных сочетаниях начальных условий по выходной координате объекта и ее производной, а также при различных значениях управляющего воздействия и. Затем компрессировали библиотеку, исключив из нее близко расположенные и совпадающие шаблоны. Если не сделать этого, при решении матричного уравнения (7) могут возникнуть проблемы из-за того, что интерполяционная матрица будет близка к особенной. Наконец, приступили к синтезу, для чего сгенерировали популяцию из 100 бинарных хромосом длиной по 1200 бит каждая.
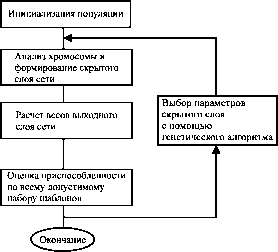
Рис. 24. Комбинированная процедура тренировки RBF-сети
Этот впечатляющий результат, возможно, приоткрывает завесу над тайнами мышления, ведь он, по существу, предлагает механизм, объясняющий эффект когнитивного сжатия, о котором говорят психологи. Отталкиваясь от огромного числа эпизодов взаимодействия с объектом, мы получили очень компактную структуру, которая концентрирует этот опыт и формирует образ объекта, который можно использовать для решения задач искусственного интеллекта классификации объектов, диагностики их состояния, прогнозирования поведения при различных стратегиях управления и так далее.
Конечно, следует отметить, что синтез столь совершенного предиктора занял довольно много времени около 50000 итераций, но, скорее, это нормально, чем ненормально, так как функциональные особенности природного интеллекта, к каковым следует отнести и длительное время обучения, не могут не перейти к искусственному интеллекту.
Получив в руки столь мощную процедуру синтеза нейроэмуляторов, мы не смогли удержаться от соблазна проверить наши догадки относительно природы мышления на концептуальной модели интеллектуальной системы управления. В своих экспериментах с ней мы пытались найти для себя ответы на следующие вопросы.
1. Предположим, нейроэмулятор действительно является неким образом, существующим в рамках условного сознания, порожденного искусственным интеллектом. Если это так, то нейроконтроллер, "мысленно" натренированный путем экспериментирования с этим отражением внешнего мира, должен уметь управлять и самим динамическим объектом.
Осуществимо ли это?
2. Можно ли на платформе развитых представлений построить адаптивную систему, которая самостоятельно могла бы улавливать изменения в объекте, перестраивать свои внутренние представления, а в конечном итоге, вырабатывать новую оптимальную стратегию воздействия на него?
3. Является ли сочетание ГА+ИНС настолько мощным в вычислительном плане, чтобы обеспечить действительно адаптивные свойства системы управления в условиях, когда характеристики объекта изменяются с течением времени самым непредвиденным образом?
Из трех вопросов наиболее сложным для нас являлся третий, потому что, не сумев ответить на него утвердительно, мы не смогли бы дать определенный ответ и на второй вопрос.
Потенциальные трудности в решении задачи адаптации видятся, прежде всего, в том, что адаптация, хотя и не является синонимом оптимизации, немыслима вне оптимизационных постановок, а процесс оптимизации должен быть сходящимся со всеми вытекающими отсюда последствиями. Любой численный метод в явном или неявном виде опирается в процессе поиска экстремума на популяцию потенциальных решений, на которой и осуществляется отбор. Но когда экстремум найден, популяция оказывается вырожденной.
Решения становятся похожими друг на друга как две капли воды, естественное разнообразие истощается и популяция теряет потенциальную способность к отслеживанию изменений в среде.
Обычный прием, который применяется для восстановления поисковой способности это полная регенерация популяции (если выполнить частичную регенерацию, сохранив хотя бы несколько особей из старой популяции, они, уже обладая неплохой приспособленностью, сыграют на фоне плохо приспособленных новых членов роль сверхиндивидов и, подобно аттракторам, притянут через своих потомков всю популяцию к себе), но его искусственность очевидна, кроме того, не ясно, как система должна догадаться, когда именно следует его применять.
Как кажется, нам удалось, если не навсегда преодолеть эту трудность, то, по крайней мере, существенно раздвинуть границы эффективной работы эволюционных методов. Выход был найден не в новых генетических операторах, а в непривычной для классической науки форме представления генетической информации а именно, в форме, заимствованной у диплоидных организмов.
СНОВА О ГЕНЕТИЧЕСКИХ АЛГОРИТМАХ
Когда мы говорили выше об эквивалентности понятий генотип в биологии и вектор переменных в математике, следовало бы оговорить, что эта эквивалентность имеет смысл только тогда, когда речь идет о гаплоидных организмах, то есть об организмах, обладающих одинарным набором хромосом. К таковым относятся бактерии, водоросли и многие другие простейшие организмы, занимающие низшие ступени эволюционного развития.
Млекопитающие, и в частности, человек, являются диплоидными организмами. В ядре каждой клетки каждого из нас (за исключением половых клеток сперматозоидов и яйцеклеток которые являются гаплоидными ) в норме содержится двойной набор из 23 хромосом. Один комплект достался нам, как известно, от отца, а другой от матери. В обоих комплектах существуют так называемые гомологичные хромосомы, кодирующие одни и те же фенотипические признаки и обладающие, в принципе, одинаковой структурой.
Так, и в отцовской, и в материнской хромосомах идентичные фрагменты кодируют цвет глаз. Тем не менее, цвет глаз ребенка зависит от того, каковы отношения доминирования между генами родителей.
О том, как регулируются в природе отношения доминантности рецессивности между гомологичными генами родительских хромосом, у биологов нет единого мнения и теперь. Разработаны различные феноменологические модели, одни из которых предполагают механизмы полного доминирования, исключающие активность гена, находящегося в рецессивном состоянии.
Другие модели допускают, что оба гена могут проявлять активность одновременно, но в разной степени (ко-доминирование).
Для нас это не так важно. В конце концов, ведь мы не ставим перед собой задачу воссоздания закономерностей, действующих в Природе. Мы можем устанавливать свои собственные законы, потому что сама эволюция у нас искусственная и нет никаких особых ограничений на то, как в наших диплоидных популяциях будут эволюционировать отношения доминантности рецессивности в генах потомства.
Существенно другое, а именно сам принцип, как передается по наследству и как декодируется в фенотипические признаки генетическая информация особей.