
Нечеткие числа и операции над ними
Заде предложил набор аналогичных операций над нечеткими множествами через операции с функциями принадлежности этих множеств. Так, если множество А задано функцией цА(и), а множество В задано функцией Цв(и), то результатом операций является множество С с функцией принадлежности рс(и), причем:
Нечеткие числа и операции над ними
Нечеткое число - это нечеткое подмножество универсального множества действительных чисел, имеющее нормальную и выпуклую функцию принадлежности, то есть такую, что а) существует такое значение носителя, в котором функция принадлежности равна единице, а также а) при отступлении от своего максимума влево или вправо функция принадлежности убывает.
Рассмотрим два типа нечетких чисел: трапециевидные и треугольные.
Трапециевидные (трапезоидные) нечеткие числа
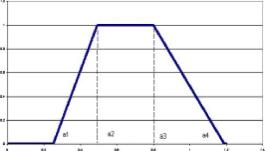
Исследуем некоторую квазистатистику и зададим лингвистическую переменную Q = Значение параметра U, где U - множество значений носителя квазистатистики. Выделим два терм-множества значений: Ті = U у лежит в диапазоне примерно от а до Ь с нечетким подмножеством Мі и безымянное значение Т2 с нечетким подмножеством М2, причем выполняется М2 = . М|. Тогда функция принадлежности рц(и) имеет трапезоидный вид, как показано на рис.
2.2.
Поскольку границы интервала заданы нечетко, то разумно ввести абсциссы вершин трапеции следующим образом:
а = (аі+а2)/2, в = (ві+в2)/2, (2.5) при этом отстояние вершин аі, а2 и вь в2 соответственно друг от друга обуславливается тем, что какую семантику мы вкладываем в понатие примерно: чем больше разброс квазистатистики, тем боковые ребра трапеции являются более пологими. В предельном случае понятие примерно выраждается в понятие где угодно.
Если мы оцениваем параметр качественно, например, высказавшись Это значение параметра является средним, необходимо ввести уточняющее высказывание типа Среднее значение - это примерно от а до Ь, которое есть предмет экспертной оценки (нечеткой классификации), и тогда можно использовать для моделирования нечетких классификаций трапезоидные числа. На самом деле, это самый естественной способ неуверенной классификации.
Треугольные нечеткие числа
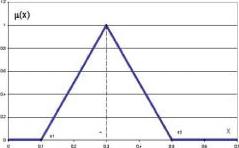
Теперь для той же лингвистической переменной зададим терм-множество TX={U приблизительно равно а}. Ясно, что а ± 8 * а, причем по мере убывания 5 до нуля степень уверенности в оценке растет до единицы. Это, с точки зрения функции принадлежности, придает последней треугольный вид (рис.
2.3), причем степень приближения характеризуется экспертом.
Треугольные числа - это самый часто используемый на практике тип нечетких чисел, причем чаще всего - в качестве прогнозных значений параметра.
Операции над нечеткими числами
Целый раздел теории нечетких множеств - мягкие вычисления (нечеткая арифметика) - вводит набор операций над нечеткими числами. Эти операции вводятся через операции над функциями принадлежности на основе так называемого сегментного принципа.
Определим уровень принадлежности а как ординату функции принадлежности нечеткого числа. Тогда пересечение функции принадлежности с нечетким числом дает пару значений, которые принято называть границами интервала достоверности.
Зададимся фиксированным уровнем принадлежности ос и определим соответствующие ему интервалы достоверности по двум нечетким числам А и В : [аь а2] и [Ьь Ь2], соответственно. Тогда основные операции с нечеткими числами сводятся к операциям с их интервалами достоверности. А операции с интервалами, в свою очередь, выражаются через операции с действительными числами - границами интервалов:
- операция сложения:
- операция вычитания:
- операция умножения:
- операция деления:
- операция возведения в степень:
[аьа2] П і=[аі1,а21]. (2.10)
Из существа операций с трапезоидными числами можно сделать ряд важных утверждений (без доказательства):
- действительное число есть частный случай треугольного нечеткого числа;
- сумма треугольных чисел есть треугольное число;
- треугольное (трапезоидное) число, умноженное на действительное число, есть треугольное (трапезоидное) число;
- сумма трапезоидных чисел есть трапезоидное число;
- сумма треугольного и трапезоидного чисел есть трапезоидное число.
Анализируя свойства нелинейных операций с нечеткими числами (например, деления), исследователи приходят к выводу, что форма функций принадлежности результирующих нечетких чисел часто близка к треугольной. Это прозволяет аппроксимировать результат, приводя его к треугольному виду.
И, если приводимость налицо, тогда операции с треугольными числами сводятся к операциям с абсциссами вершин их функций принадлежности.
То есть, если мы вводим описание треугольного числа набором абсцисс вершин (а, Ь, с), то можно записать:
(аь bi, сі) + (а2, b2, с2) = (аі + а2, bi + b2, сі + с2). (2.11)
Это - самое распространенное правило мягких вычислений.
Нечеткие последовательности, нечеткие
прямоугольные матрицы, нечеткие функции и операции над ними
Нечеткая последовательность - это пронумерованное счетное множество нечетких чисел.
Нечеткая прямоугольная матрица - это дважды индексированное конечное множество нечетких чисел, причем первый индекс пробегает М строк, а второй - N столбцов. При этом, как и в случае матриц действительных чисел, операции над нечеткими прямоугольными матрицами сводятся к операциям над нечеткими компонентами этих матриц. Например,
где все операции над нечеткими числами производятся так, как они введены параграфом выше.
Поле нечетких чисел - это несчетное множество нечетких чисел.
Нечеткая функция - это взаимно однозначное соответствие двух полей нечетких чисел. В наших приложениях область определения нечеткой функции явзяется осью действительных чисел, то есть вырожденным случаем поля нечетких чисел, когда их треугольные функции принадлежности вырождаются в точку с координатами (а, 1).
Нечеткую функцию уместно назвать по типу тех чисел, которые характеризуют область ее значений. Если поле значений - это поле треугольных чисел, то и саму функцию уместно назвать треугольной.
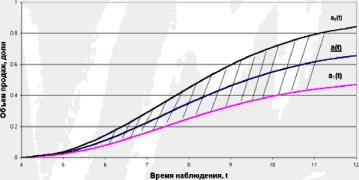
Например, прогноз продаж компании (нарастающим итогом) задан тремя функциями вещественной переменной: fi(T) - оптимистичный прогноз, f2(T) - пессимистичный прогноз, f3(T) - среднеожидаемые значения продаж, где Т - время прогноза. Тогда лингвистическая переменная Прогноз продаж в момент Т есть треугольное число ( fi(T), f2(T), f3(T)), а все прогнозное поле есть треугольная нечеткая функция (рис.
2.4), имеющая вид криволинейной полосы.
Рассмотрим ряд операций над треугольными нечеткими функциями (утверждения приводятся без доказательства):
- сложение: сумма (разность) треугольных функций есть треугольная функция;
- умножение на число переводит треугольную функцию в треугольную функцию;
- дифференцирование (интегрирование) треугольной нечеткой функции проводится по правилам вещественного дифференцирования (интегрирования):
А( f,(T), f2(T), f3(T)) = (Afl(T), ±f2(T), Af,(T) , dT dT dT dT (2.13)
I ( fi(T), f2(T), f3(T)) dT = ( J fi(T)dT, \ f2(T) dT, \ f3(T) dT ) (2.14)
- функция, зависящая от нечеткого параметра, является нечеткой.
Вероятностное распределение с нечеткими параметрами
Пусть имеется квазистатистика и ее гистограмма и пусть одна из возможных плотностей вероятностной функции распределения, приближающая квазистатистику, обозначается нами как р(и, К), где и -значение носителя, u е U, К = (хь..., xN) - вектор параметров распределения размерностью N.
Произведем гипотетический эксперимент. Оценим вид функции распределения р(), производя вариацию всех параметров вектора N. При этом зададимся критерием правдоподобия нашего распределения -унимодальной гладкой функцией без изломов и разрывов (например, квадратичной многомерной параболой) - и пронормируем значение критерия. Например, если максимум правдоподобия имеет значение L, то вектор параметров N приобретает значение, которое мы будем называть контрольной точкой или точкой ожидания с координатами (x1L,..., xNL) . Мы можем производить нормирование правдоподобия, задавшись некоторым процентом максимума правдоподобия, ниже которого наши вероятностные гипотезы бракуются.
Тогда всем правдоподобным вероятностным гипотезам отвечает множество векторов N , которое в N-мерном фазовом пространстве представляет собой выпуклую область с нелинейными границами.
Впишем в эту область N-мерный параллелепипед максимального объема, грани которого сориентированы параллельно фазовым осям. Тогда этот параллелепипед представляет собой усечение N и может быть описан набором интервальных диапазонов по каждой компоненте
N =(X11,X12;X21,X22;...XN1,XN2) е N . (2.15)
Назовем N зоной предельного правдоподобия. Разумеется, контрольная точка попадает в эту зону , то есть выполняется
ХцХіь Xi2,...,XNiXNL xN2, (2.16)
что вытекает из унимодальности и гладкости критерия правдоподобия.
Тогда мы можем рассматривать числа (xlb хц,, xl2) как треугольные нечеткие параметры плотности распределения, которая и сама в этом случае имеет вид нечеткой функции. А зона предельного правдоподобия тогда есть не что иное, как нечеткий вектор.
Мы видим, что полученное вероятностное распределение имеет не только частотный, но и субъективный смысл, так как зона предельного правдоподобия зависит от того, как мы бракуем вероятностные гипотезы. Представляется, что такое описание всецело отвечает природе квазистатистики, как мы ее здесь вводим. Чем хуже условия для выдвижения правдоподобных вероятностных гипотез, чем тяжелее обосновывать такое правдоподобие, - тем большее значение занимает фактор экспертной оценки.
То вероятностное описание, что мы имеем в итоге, - это гибрид, который обещает быть плодотворным.
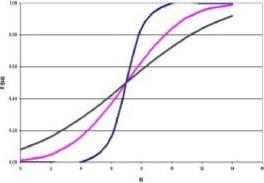
В качестве примера можно рассмотреть нормальный закон распределения с нечетким среднеквадратическим отклонением (рис. 2.5).
Эта нечеткая функция не имеет полосового вида. И тут замое время заметить, что функция с треугольными нечеткими параметрами в общем случае сама не является треугольной и к треугольному виду не приводится.
Зато выполняется нормировочное условие: где правая часть представляет собой нечеткое число с вырожденной в точку функцией принадлежности. Интеграл же, не определенный для не четких функций общего вида, представляет здесь предел сумм
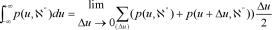
Приложим все сказанное к нечеткой оценке параметров доходности и риска фондового индекса. Пусть у нас есть квазистатистика доходностей (гь ...rN) мощности N и соответствующая ей гистограмма (?і,...,?м) мощности М. Для этой квазистатистики мы подбираем двупараметрическое нормальное распределение ср(*) с матожиданием р и дисперсией а, руководствуясь критерием правдоподобия
-oo
p(u, N' )du = 1,
(2.17)
-00
(2.19)
^ -yf
F(//,cr) = -^(-^-^(i-,po))2 max,
1=1 Аг
где г, - отвечающее і-му столбцу гистограммы расчетное значение доходности, Дг - уровень дискретизации гистограммы.
Задача (2.19) - это задача нелинейной оптимизации, которое имеет решение (2.20)
причем цо, ao - аргументы максимума F(p,a), представляющие собой контрольную точку.
Выберем уровень отсечения F! F0 и признаем все вероятностные гипотезы правдоподобными, если соответствующий критерий правдоподобия лежит в диапазоне от Fi до F0. Тогда всем правдоподобным вероятностным гипотезам отвечает множество векторов К, которое в двумерном фазовом пространстве представляет собой выпуклую область с нелинейными границами.
Впишем в эту область прямоугольник максимальной площади, грани которого сориентированы параллельно фазовым осям. Тогда этот прямоугольник - зона предельного правдоподобия - представляет собой усечение К и может быть описан набором интервальных диапазонов по каждой компоненте
(2.21)
^ (Рпшъ Ртах? ^тііъ *Тпах) ^ ^
Разумеется, контрольная точка попадает в эту зону, то есть выполняется
РпшА Ро ^Ртах? ^min ^ tT() (5max (2.22)
что вытекает из унимодальности и гладкости функции правдоподобия.
Тогда мы можем рассматривать числа р = (pmm, р0, ртах), = (сттт, ст0, атах) как треугольные нечеткие параметры плотности распределения ср(), которая и сама в этом случае имеет вид нечеткой функции.
Нечеткие знания
Назовем формальным знанием высказывание естественного языка, обладающее следующей структурой:
ЕСЛИ(АіТ7! А2^2... An-^n-jAn), ТО В, (2.23)
где {Аі}, В - атомарные высказывания (предикаты), Т( - логические связки вида И/ИЛИ, N - размерность условия, причем атомарные высказывания -это
а?Х, (2.24)
где а - определяемый объект (аргумент), ? - логическая связка принадлежности вида ЕСТЬ/НЕ ЕСТЬ, X - обобщение (класс объектов). Также соблюдается правило очередности в рассмотрении фразы для понимания: сначала все связки И применяются к двум смежным предикатам, а затем все связки ИЛИ применяются к результатам предшествующих операций.
Например, классический вывод Если Сократ человек, а человек смертен, то и Сократ смертен можно преобразовать к структуре формального знания по следующим правилам:
- вводится два класса объектов X! = Человек (Люди) и Х2 =
Смертный (-ая, -ое);
- рассматриваются два аргумента: аі = Сократ, а2 = Человек = X,.
Тогда наше знание имеет формулу
ЕСЛИ aj ЕСТЬ Хх И (а2 = Хх) ЕСТЬ Х2
ТО ЕСТЬ Х2 (2.25)
Очень часто в структуре знаний классы объектов являются нечеткими понятиями. Также высказывающиеся лица могут делать выводы, содержащие элементы неуверенности, оценочности.
Это заставляет нас переходить от знаний в классическом понимании к знаниям нечетким.
Введем следующий набор лингвистических переменных со своим терм-множеством значений:
? = Отношение принадлежности = (Принадлежит, Скорее всего принадлежит, Вероятно принадлежит,...., Вероятно не принадлежит, Скорее всего не принадлежит, Не принадлежит}
(2.26)
А = Отношение следования = (Следует, Скорее всего следует, Вероятно следует,...., Вероятно не следует, Скорее всего не следует, Не следует }
(2.27)
{И/ИЛИ, Скорее всего И/ИЛИ,
(2.28)
AND/OR = Отношение связи
В ероятно И/ИЛИ...}
Вводя эти переменные, мы предполагаем, что они содержат произвольное число оттеночных значений, ранжированных по силе (слабости) в определенном порядке. Носителем этих переменных может выступать единичный интервал.
Тогда под нечетким знанием можно понимать следующий формализм:
ЕСЛИ(аі?іХі Т*] аг?гХг ТС... а^?^Х^) А а^+1?^+1Х^+1, (2.29) где а,, X, -значения своих лингвистических переменных, ?, -значение переменной принадлежности из ?, Т7, -значение переменной связи из AND/OR, А - терм-значение переменной следования из А.
Характерным примером нечеткого знания является высказывание типа: Если ожидаемое в ближайшей перспективе отношение цены акции к доходам по ней порядка 10, и (хотя и не обязательно) капитализация этой компании на уровне 10 млрд, долларов, то, скорее всего, эти акции следует покупать. Курсивом обозначены все оценки, которые делают это знание нечетким.
Поскольку нечеткое знание определяется через лингвистические переменные, то и операции нечеткого логического вывода можно количественно определить на базе операций с соответствующими функциями принадлежности. Однако детальное рассмотрение этого вопроса мы опускаем.
С некоторых пор нечеткие знания начали активно применяться для выработки брокерских рекомендаций по приобретению (удержанию, продаже) ценных бумаг. Например, монография [Регау] рассматривает вопрос о целесообразности инвестирования в фондовые активы в зависимости от характера экономического окружения, причем параметры этого окружения являются нечеткими значениями.
На сайте [Регау homepage] автор вышеупомянутой монографии поддерживает бюллетень макроэкономических индикаторов и соответствующих условий инвестирования на тех или иных рынках.
На нечетких знаниях могут быть организованы специализированные экспертные системы, реализующие механизм нечетко-логического вывода. Простейший пример такого рода системы мы находим на сайте [Option Advisor], где выработка опционной стратегии сопровождается нечеткой предварительной оценкой характера рынка.
В этом смысле также представляет интерес и заслуживает упоминания работа [Тгіррі].
Нечеткие классификаторы и матричные схемы агрегирования данных
Определим в качестве носителя лингвистической переменной отрезок вещественной оси [0,1]. Любые конечномерные отрезки вещественной оси могут быть сведены к отрезку [0,1] путем простого линейного преобразования, поэтому выделенный отрезок единичной длины носит универсальный характер и заслуживает отдельного термина.
Назовем носитель вида [0,1] 01- носителем.
Теперь введем лингвистическую переменную Уровень показателя с терм-множеством значений Очень низкий, Низкий, Средний, Высокий, Очень Высокий. Для описания подмножеств терм-множества введем систему из пяти соответствующих функций принадлежности трапециедального вида:
1, 0 х 0.15
(2.30.1)
(2.30.2)
щ (х) = 110(0.25 - х), 0.15 х 0.25 . 0, 0.25 х1
0, 0 х 0.15 10(х-0.25), 0.15 х 0.25 д2(х) = 1, 0.25 х 0.35
10(0.45 -х), 0.35 х 0.45 0,0.45 х = 1
к '
0, 0 x 0.35 10(x - 0.35), 0.35 x 0.45 1, 0.45 x 0.55 10(0.65 -x), 0.55 x 0.65 0, 0.65 x = 1
0, 0 x 0.55 10(x - 0.55), 0.55 x 0.65 1, 0.65 x 0.75 10(0.85 -x), 0.75 x 0.85 0, 0.85 x = 1
0, 0 x 0.75
10(x -0.75), 0.75 x 0.85 .
1, 0.85 xl
(2.30.3)
Ш(х) = *
(2.30.4)
Mx) =
(2.30.5)
Mx) =
Везде в (2.30) x - это 01-носитель. Построенные функции принадлежности приведены на рис.
2.6.
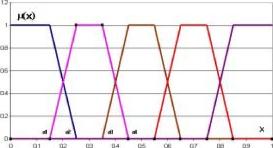
Введем также набор нак называемых узловых точек а, = (0.1, 0.3, 0.5, 0.7, 0.9), которые являются, с одной стороны, абсциссами максимумов соответствующих функций принадлежности на 01-носителе, а, с другой стороны, равномерно отстоят друг от друга на 01-носителе и симметричны относительно узла 0.5.
Тогда введенную лигвистическую переменную Уровень фактора, определенную на 01-носителе, в совокупности с набором узловых точек здесь и далее будем называть стандартным пятиуровневым нечетким 01-классификатором.
Сконструированный нечеткий классификатор имеет большое значение для дальнейшего изложения. Его суть в том, что если о факторе неизвестно ничего, кроме того, что он может принимать любые значения в пределах 01-носителя (принцип равнопредпочтительности), а надо провести ассоциацию между качественной и количественной оценками фактора, то предложенный классификатор делает это с максимальной достоверностью.
При этом сумма всех функций принадлежности для любого х равна единице, что указывает на непротиворечивость классификатора.
Если при распознавании уровня фактора эксперт располагает дополнительной информацией о поведении фактора (например, гистограммой), то классификация фактора в общем случае не будет иметь стандартного вида, потому что узловые точки классификации и соответствующие функции принадлежности будут лежать несимметрично на носителе соответствующего фактора.
Также, если существует набор из і= 1.. N отдельных факторов со своими текущими значениями хь и каждому фактору сопоставлен свой пятиуровневый классификатор (необязательно стандартный, необязательно определенный на 01-носителе), то можно перейти от набора отдельных факторов к единому агрегированному фактору A N, значение которого распознать впоследствии с помощью стандартного классификатора. Количественное же значение агрегированного фактора определяется по формуле двойной свертки:
N 5A_N = ZPiSajPij(xi), (2.31)
1=1 j=l
где a, - узловые точки стандартного классификатора, р, - вес і-го факторов в свертке, ц,, (х,) - значение функции принадлежности j-ro качественного уровня относительно текущего значения і-го фактора. Далее показатель A N может быть подвергнут распознаванию на основе стандартного нечеткого классификатора, по функциям принадлежности вида (2.30).
Из формулы (2.31) становится понятным назначение узловых точек в нечетком классификаторе. Эти точки выступают в качестве весов при агрегировании системы факторов на уровне их качественных состояний.
Тем самым узловые точки осуществляют сведение набора нестандартных классификаторов (со своими нессиметрично расположенными узловыми точками) к единому классификатору стандартного вида, с одновременным переходом от набора нестандартных носителей отдельных факторов к стандартному 01-носителю.
Можно построить матрицу, где по строкам расположены факторы, а по столбцам - их качественные уровни. На пересечении строк и столбцов лежат значения функций принадлежности соответствующих качественных уровней. Дополним матрицу еще одним столбцом весов факторов в свертке р! и еще одной строкой с узловыми точками а]. Тогда для расчета агрегированного показателя A N по (2.31) в полученной матрице собраны все необходимые исходные данные.
Поэтому предлагаемую здесь схему агрегирования данных целесообразно назвать матричной.
Матричные схемы на основе пятиуровневых классификаторов уже давно и довольно успешно применяются для комплексной оценки уровня функционирования многофакторных систем, в том числе и финансовых (например, финансов корпорации). Об этом речь быдет идти в главах 3, 5 и 8 настоящей книги.
Все изложение данного параграфа базируется на пятиуровневом классификаторе. На самом же деле, уровней в классификаторе может быть произвольное число, и все определяется лишь удобством моделирования. Простейший классификатор - бинарный (хорошо-плохо, высоко-низко), но он представляется слишком грубым, т.к. не фиксирует характерного среднего положения, вокруг которого и группируется большинство количественных состояний в реальной жизни.
Отвлеченнная аналогия: крайности жизни особенно выпукло наблюдаются с позиций мещанской середины (об этом Степной Волк Г.Гессе). Поэтому целесообразно говорить о стандартном трехуровневом нечетком 01-классификаторе (состояния Низкий, Средний, Высокий) с функциями принадлежности следующего вида (рис. 2.7):
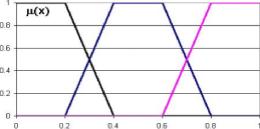
Pi 00 =
Р2(х) =
Рз(х) =
1, 0 x 0.2 5(0.4-х), 0.2 х 0.4 1, 0.4 х 1
0, 0 х 0.2 5(х - 0.2), 0.2 х 0.4 1, 0.4 х 0.6 5(0.8 - х), 0.6 х 0.8 О, 0.8 х = 1
0. 0 х 0.6 5(х-0.6),0.6х 0.8.
1. 0.8 х 1
(2.32.1)
(2.32.2)
(2.32.3)
Аналогично, матричная схема агрегирования данных на основе трехуровневых классификаторов базируется на формуле:
N 3
A_N = ZPiZajPij(xi)- (2-33)
i=i j=i
Итак, изложение базовых формализмов теории нечетких множеств завершено. Посмотрим, чем все-таки они могут нам помочь.
Финансовый менеджмент в расплывчатых условиях
Финансовый анализ и опенка риска банкротства
З. Существующие подходы
Главное внимание инвестора в ценные бумаги эмитента должно быть сфокусировано на финансовом здоровье эмитента. Вкладывая деньги, инвестор (или собственник) рассчитывает получить доход как в форме дивидендов по акциям, процентов по долговым обязательствам, так и в виде курсового роста соответствующих инвестиционных инструментов.
Ухудшение финансового здоровья эмитента, сопровождающееся ростом его долгов, вызывает риск срыва платежей по обязательствам, прекращения любых выплат и сворачивания деятельности неудачливого субъекта рынка.