
Системы одновременных уравнений
Пакет Stata обладает весьма обширным набором средств, позволяющих учитывать стратификационный характер выборок это около двух десятков комманд с префиксом svy. Для использования этих команд необходимо указать, какие переменные несут в себе информацию о структуре выборке (svyset и svydes). Иногда вместо svy-команд можно воспользоваться опцией , cluster (), которую можно использовать с большинством команд Stata, оценивающих параметрические модели, в т.ч. с коман-
дой regress. Для уточнения оценок параметров и вторых моментов регрессионнвіх моделей можно исполвзоватв веса (см. help weights), связаннвіе с вероятноствю включения в ввіборк? отделвнвіх наблюдений (т.е. веса, ?читвівающие стратификационное происхождение ввіборки) pweight (сокр. от probability weights) если такие веса входят в базві даннвіх обследований.
Системы одновременных уравнений
Подобные модели описывают явления, в которых несколько переменных определяется одновременно, как некоторое равновесие экономической системы. Типичным примером СОУ является равновесие рыночных спроса и предложения.
Проблема одновременности тесно связана е уже упоминавшейся проблемой етоха-етичноети регрессоров. Дело в том, что эндогенные переменные (т. е. переменные, определяемые в равновесии; сопутствующее понятие экзогенные, или заданные извне, переменные) коррелированы е ошибками, и поэтому оценивание по методу наименьших квадратов приводит к смещенным и несостоятельным оценкам.
В зависимости от структуры уравнений, коэффициенты при эндогенных переменных могут быть, а могут и не быть идентифицируемы.
Для разрешения проблемы эндогенности используются двух- и трехшаговый метод наименьших квадратов (3SLS).
Stata
И соответствующая команда называется reg3.
Модели с дискретными и другими ограниченными зависимыми переменными
Часто возникает потребность в анализе моделей, в которых в качестве зависимой переменной фигурирует качественная величина, например, наличие-отсутствие или отказ-участие. Естественным образом такие величины кодируются как 0/1 и называются на статистическом жаргоне "успех-неуспех".
Они имеют (условное) биномиальное распределение. Метод наименьших квадратов, применяемый напрямую, будет как минимум страдать от гетероскедастичности: ошибки должны быть устроены так, чтобы в результате получилось значение 0 или 1. Возможно, что для каких-то наблюдений и в случае успеха, и в случае неуспеха ошибка должна быть отрицательной (или положительной), и тогда будет нарушаться и предположение об (условной) центральности ошибок.
Для разрешения подобных трудностей моделируется непосредственно вероятность успеха (т, е, регистрации 1 в принятой кодировке исходов). При дополнительном предположении наличия индексной функции, являющейся линейной комбинацией известных переменных,
P(y = 1|x) = F (xT в)
P (y = 0|x) = 1 F (хтв) (2,59)
Эта величина должна лежать в промежутке [0,1], что накладывает ограничения на вид функции F, Чаще всего в качестве этой функции используется та или иная функция распределения, В подавляющем большинстве работ используется одна из двух функций распределения стандартной нормальной величины или логистического распределения:
F(z) = T+dp(Z) М
Соответствующие модели носят название пробит- и логит-моделей; для второй еще используется название логистическая регрессия. Существенных оснований предпочитать одну модель другой, видимо, нет.
Обе функции распределения симметричны, а различия между ними не так велики: supX?(-(X,+x) |F1ogit(x) FN(o,i)(x) | 0.02, но у логистического распределения более тяжелые хвосты. Пробит-модель привлекательна тем, что в ней используется самое типичное распределение в мире нормальное, и поэтому она удобна для анализа моделей с многомерным нормальным распределением ошибок, если зависимых переменных несколько, В качестве примера можно привести модель Хекмана регрессии с внешним выбором наблюдений (Heckman sample selection model) , С другой стороны, логит-модель допускает достаточно широкий спектр средств анализа качества приближения (goodness of fit),
Иногда встречается также асимметричная функция дополнительных логарифмов, называемая также функцией Гомперца (Gomperz, соответственно, гомпит/gompit-модель):
F(z) = 1 exp[- exp(z)] (2,61)
Stata
Соответствующие регрессии в пакете Stata вызываются командами probit, logit и cloglog.
Оценивание коэффициентов в данных моделях производится по методу максимального правдоподобия. Если наблюдения независимы, то функция правдоподобия для отдельных наблюдений имеет вид:
F (xT в), Уі
1 F (xI Р), Уі
(2.62)
L(yji,Xi,e,F)
что может быть очень удачно переписано как
(2.63)
L (уі , Xi ,e,F) = F (xT в) (1 F (xT в))1-*
Тогда общая функция правдоподобия имеет вид:
In L(y, X,e,F) = ІУі ln F(xi в) + (1 Уі)1п(1 F(xi в))} (2-64)
i= 1
Задача максимизации этой функции по в решается численными методами.
Одним из очень существенных достоинств пакета Stata является доступ программистов к алгоритму численного решения задач максимизации функции правдоподобия пользователя (Gould, Sribnev 1999). Оценивание по методу максимального правдоподобия осуществляется командами набора ml.
К оценкам коэффициентов пробит- и логит-регрессий относятся все комментарии о методе максимального правдоподобия (Кендалл, Стьюарт 1973), В определенном классе оценок оценки максимального правдоподобия являются асимптотически эффективными, однако они очень чувствительны к нарушениям формы распределения. Тесты на значения коэффицентов или их линейных комбинаций (в т.ч, на значимость регрессии в целом) осуществляются с помощью статистики отношения правдоподобия или ее асимптотических аналогов теста Вальда (Wald test) и множителей Лагранжа (LM test,
Lagrange multiplier test, score test). Bee эти тесты имеют асимптотическое распределение х2 с числом степеней свободы, равном числу накладываемых ограничений (Айвазян, Мхитарян 1998, Greene 1997),
Определенное неудобство логит- и пробит-моделей (как, впрочем, и всех нелинейных моделей) заключается в том, что оценки коэффициентов, в отличие от линейной регрессии, не могут быть интепретированы как предельные эффекты (т.е. изменения зависимой переменной при измененении независимой, в том числе бинарной, на единицу), поскольку предельные эффекты в нелинейных моделях зависят от точки, в которой берется такое приращение. Для того, чтобы получить хоть какое-то представление о предельных эффектах, можно рассчитать предельные эффекты для выборочного среднего по всем независимым переменным, или рассчитать предельные эффекты во всех точках и усреднить.
В шестой версии функцию расчета предельных эффектов для пробит-модели выполняет команда dprobit, которая оценивает пробит-модель точно так же, как probit, но вместо коэффициентов выводит предельные эффекты для выборочных средних всех регрессоров. В седьмой версии пакета Stata появилась очень удобная команда mfx, которая рассчитывает эти самые предельные эффекты для произвольной оцененной модели.
Квантильные регрессии
Иногда предметом интереса исследователя могут быть не средние значения зависимой переменной при фиксированных объясняющих, а определенные квантили распределения:
(2.65)
P[y m\x) = р
В исследованиях финансового риска интерес могут представлять, к примеру, 5% или 10% точки (р = 0.05 или 0.1), Кроме того, знание набора (условных) квантилей позволит понять, меняется ли форма распределения в зависимости от объясняющих переменных. Примером квантильной регрессии является упоминавшаяся ранее в контексте проблем робастности условная медиана при р = 0.5,
Stata
Квантильные регрессии реализованы в пакете Stata командой qreg. Опция qreg ... ,
quantile О этой команды позволяет явно указатв, квантили какого уровня p следует исследоватв.
Можно показать, что медианная регрессия является решением задачи минимизации суммы абсолютных отклонений (ср, (2,11)):
N
^ |Уі - Xiв| ^ min (2,66)
i= 1
Данная задача решается симплекс-методом или другими методами линейного программирования.
Непараметрические регрессии
Методы непараметрической регрессии являются формализацией интуитивного понятия сглаживания "на глаз". Если мы будем проводить на глаз кривую на двумерном графике рассеяния, чтобы описать примерный вид зависимости E [y|x], мы будем учитывать, где лежат наблюденные значения у вблизи интересующей нас точки х, повторяя характерные пики и впадины кривой регрессии (см,, например, рис, 2,3),
Непараметрическая оценка кривой регрессии имеет вид:
m(x) = n 1 ^ Wni(x)yi, (2,67)
i= 1
где Wni веса сглаживания, которые могут зависеть от всего вектора х, В такой постановке задачу сглаживания можно интерпретировать как задачу нахождения оценки локально взвешенных наименьших квадратов:
П
n -1 ^ Wni(x)(yi - rm(xi))2 ^ min (2,68)
' ^ mix')
i= 1
Один из методов, явно использующий многократно прогоняемые регрессии для локального сглаживания lowess (locally weighted smoothing) (Fox 1997, Хардле 1993). Его реализация в пакете Stata осуществлена командой ksm с опцией ksm ... , lowess.
В эконометрической литературе варианты непараметрической регрессии известны под названиями локальной регрессии (local regression) и "скользящей" регрессии (rolling regression), В них используется та же самая идея локального взвешивания.
Формализация близости заключается во введении "ядра сглаживания" с определенной "шириной окна". Точки, не попадающие в ядро, будут иметь нулевой вес; таким образом, внимание процедуры сглаживания будет сосредоточено вблизи требуемой точки. Понятие ядра и его применение в непараметрической регрессии формализуется следующим образом (Хардле 1993):
| Wni(x) = Khn (x Xi)/fhn (x) | (2.69) |
| fhn (x) = n-1J2 Khn (x Xi) i= 1 |
(2.70) |
| Khn (u) = h-1 K (u/hn) | (2.71) |
| / K(u)du = 1 | (2.72) |
Полученная таким образом ядерная оценка функции регрессии носит название оценки Надарая-Ватсона.
Есть ряд наиболее популярных ядерных функций:
ядро Епанечникова: K(u) = 0.75(1 u2)I(|u| 1)
15
квартичеекое ядро: K(u) = (1 u2)2I(|u| 1)
16
равномерное ядро: K (u) = -1 (|u| 1)
треугольное ядро: K(u) = (1 |u|)I(|u| 1)
1
(2.73)
(2.74)
(2.75)
(2.76)
(2.77)
нормальное (гауссово) квазиядро: K (u)
exp[u2/2]
?2П
Здесь I(устовие) индикаторная функция, принимающая значение 1, если условие выполняется, и 0, в противном случае.
Если по отношению к параметрическим моделям всегда могут возникнуть вопросы: "Почему именно такая спецификация модели? Почему именно такая форма ошибок?", то естественные вопросы к непараметрическим моделям "Почему именно такая форма ядра? Почему именно такая ширина окна?". Есть результаты, показывающие, что ядерная оценка будет состоятельна независимо от выбора ядра, однако ядро Епанечникова обладает определенными оптимальными свойствами в смысле среднеквадратической ошибки.
Что же касается выбора ширины окна hn, то выбор слишком малого значения будет означать, что оценка кривой регрессии пройдет через все точки выборки, тогда как слишком большое значение сгладит истинную кривую слишком сильно , Со статистической точки зрения, задача заключается в том, чтобы соблюсти компромисс между дисперсией точечной оценки и ее смещением. Асимптотически максимальная скорость сходимости среднеквадратической ошибки прогноза составляет в одномерном случае n-4/9 (т, е, медленнее, чем в параметрических задачах), а ширина окна при этом пропорциональна n-1/9.
Непараметрическая регрессия выполняется командой kernreg, входящей в состав дополнения STB-30. Данная команда позволяет указать тип ядра (Епанечникова по умолчанию, равномерное, нормальное, квартическое, триквартическое, треугольное, косинусоидальное), ширину окна, а также точки, в которых будет произведена оценка.
Непараметрическая оценка плотности осуществляется встроенной командой kdensity, которая изначально существовала как команда STB, а потом стала частью официального дистрибутива Stata.
Наиболее существенным недостатком непараметрической регрессии является ее одномерность, Обобщение на случай многомерного вектора объясняющих переменных, безусловно, возможно достаточно использовать многомерные плотности, или произведения одномерных ядер однако число соседей убывает с ростом размерности очень быстро (эффект, известный под названием "проклятие высокой размерности", dimensionality curse), и окно приходится распространять чуть ли не на всю выборку. Кроме того, в многомерных задачах меняется и скорость сходимости, причем, конечно же, в сторону ухудшения.
Во всяком случае, упомянутая выше реализация алгоритма непараметрической регрессии рассчитана на единственный регрессор.
Я бы порекомендовал дополнять параметрические оценки регрессии непараметрическими в целях проверки точности подгонки. Сведенные на одном графике диаграмма рассеяния, предсказанные значения и непараметрическая оценка позволят выявить основные дефекты регрессии: неучтенную нелинейность, гетероскедастичность нт, п,,
как это сделано на рис, 2,3,
Программа Stata (StataCorp, 1999, 2001) это универсальный пакет для решения статистических задач в самых разных прикладных областях: экономике, медицине, биологии, социологии. Впервые пакет вышел на рынок под этим названием в начале 80-х гг, В январе 1999 г, была выпущена шестая версия, в декабре 2000 г, седьмая. Основными достоинствами Stata являются:
- большой спектр реализованных статистических методов (хотя и сеть методы, не реализованные практически никак, например, дискриминантный анализ, кластерный анализ, обобщенный метод моментов, ряд других);
- возможности гибкой пакетной обработки данных (т, е, программирования всей последовательности команд, начиная от загрузки данных в память и вплоть до всех деталей анализа). Возможности интерактивного режима работы полностью идентичны возможностям пакетной обработки;
- относительная простота написания собственных программных модулей, и, вместе с тем, весьма серьезный спектр средств программирования;
- мощная поддержка как со стороны производителя, так и со стороны других пользователей Stata (через интернетовский список рассылки); огромный архив пользовательских программ в открытом доступе;
- возможность максимизации функций правдоподобия, задаваемых пользователем;
- наличие совместимых по функциональным возможностям и форматам данных реализаций для большинства популярных платформ (Windows, Macintosh, UNIX),
По поводу графических средств мнения пользователей разнятся: с одной стороны, они вполне достаточны для текущего графического анализа данных и подготовки научных публикаций (вес рисунки в этой книге выполнены в Stata и импортированы в LTEX), с друГОй; несравнимы е графическими возможностями специализированных пакетов типа Harvard Graphics или презентационных программ типа PowerPoint,
Ниже будет приведена сводка наиболее важных команд пакета. Эта сводка вряд ли сможет заменить изучение этих (и, естественно, других) команд по руководствам пользователя или хотя бы по встроенной подсказке Stata (например, не вес детали синтаксиса и не вес опции могут быть упомянуты в данном кратком введении).
Скорее, она поможет найти, какими командами и для чего следует воспользоваться; более полное и точное описание этих команд можно найти во встроенной помощи Stata и в руководствах, Многие команды будут упомянуты лишь на уровне названия (что, впрочем, достаточно для поиска по встроенной подсказке Stata), Читателю настоятельно советуется, овладеть и пользоваться, встроенной помощью Stata по командам и деталям внутреннего устройства па,кета.
Договориться: обозначения
Мы будем пользоваться следующими обозначениями, выдержанными в стиле руководств Stata, Так, command команда, которую можно набирать целиком, а можно сократить до первых трех букв (например, regress можно написать как reg, а можно как regress), [в квадратных скобках] будут указаны необязательные фрагменты команды необязательные опции, списки переменных и т, п. Курсивом мы будем обозначать то, что пользователь подставляет по своему разумению названия переменных, численные значения параметров программ и т, п. Через вертикальную черту будут перечисляться возможные варианты: івариант 1\ва,ри,а,н,т 21. Таким образом, запись describe [ переменные I using имя файлаі может разворачиваться в следующие варианты: d
describe
describe xl x2 x3 d using source desc using source.dta
Эта команда выдает краткое описание файла данных в памяти Stata или на диске.
Ссылки на руководства также оформляются в стиле Stata: [R] команда означает, что эту команду можно найти в четырехтомном справочнике команд (Reference); [U] 3 A brief description of Stata это ссылка на Руководство пользователя, а именно на главу 3 в книге User’s Guide (для Stata 6) описание Stata в руководстве пользователя (то, что можно почитать о Stata вместо этого параграфа); [G] twoway описание двумерных графиков в руководстве по графике.
Открыть: установка и запуск Stata
Обычно Stata устанавливается в каталог с:/stata, сели при установке не было явно указано иное. Исполняемый файл называется wstata.exe (Stata for Windows).
Команда verinst проверяет корректность установки пакета.
Сам этот исполняемый модуль выполняет сравнительно небольшое число (около 200) базовых процедур. Подавляющее большинство собственно статистических задач выполняется внешними программами с расширением .ado, находящимися в каталоге с: /stata/ado и его подкаталогах.
Эти ado-файлы с некоторой степенью условности можно разделить на базовые (около 900), отлаженные разработчиком и входящие в комплект поставки Stata, (хотя и в них иногда находят ошибки, и тогда Stata делает официальные обновления ado-файлов); официально распространяемые, входящие в состав официальных дополнений к Stata Stata Technical Bulletin, сокращенно STB, которые рассылаются подписчикам и распространяются бесплатно через Internet; и, наконец, пользовательские.
При запуске Stata устанавливает ряд внутренних параметров, таких, как объем выделяемой памяти, и некоторые другие (о них можно узнать в [R] limits или в подсказке help limits). Практически наверняка вам придется менять следующие установки: set memory объем, памятиfk|m]
Объем памяти, выделяемой операционной системой для Stata. Чтобы отвести 10 мегабайт, надо напечатать: set memory 10m. Можно выделить память при запуске па-
раметром командной строки: wstata /к 10240. Если количество переменных ограничено 2047, то количество наблюдений может бвітв ограничено толвко возможноствю выделения памяти операционной системой. При выделении количества памяти, приближающейся к физическому объему ОЗУ (или тем более превышающего этот объем), Stata начинает полвзоватвся виртуалвной памятвю (постоянно перезагружаемой с жесткого диска), и работа может замедлятвся в сотни раз. set matsize число
Максималвный размер матрицы, которую Stata сможет обработатв. По умолчанию устанавливается 10.
Максималвный размер 800. Этот параметр влияет на размерности статистических моделей, которые Stata будет в состоянии оценитв.
Stata может быть запущена в пакетном режиме, в котором она обрабатывает заданную в качестве входного параметра программу \ а по завершении выполнения этой программы передает управление операционной системе (или, попросту говоря, самоликвидируется). Такой вариант запуска задается (в Windows) как wstata /Ь do имя файла с программой.
Выход из Stata осуществляется командой exit . Если при этом данные не были сохранены, Stata об этом напомнит.
См. также: [U] 5 Starting and stopping Stata, [U] 6 Troubleshooting starting and stopping Stata
Придти, увидеть, посчитать: интерфейс Stata
Внешний вид Stata (рис. 3.3) несколько отличен от того, что обычно можно увидеть в других етатиетичееких пакетах.
Внешний аскетизм интерфейса унаследован от идеологии командной строки UNIX, и пользователю Windows требуется некоторое привыкание.
Stata использует в работе несколько окон: окно ввода команд (Stata Command), окно вывода результатов (Stata Results), окно истории, или предыдущих команд (Review), окно переменных (Variables), окно поиска и помощи (Help), графический экран (Graph), окно файла-протокола, или log-файла (Log; в 7-й версии его функцию выполняет окно Viewer). Можно также вызвать окна просмотра данных (Stata Browser) или
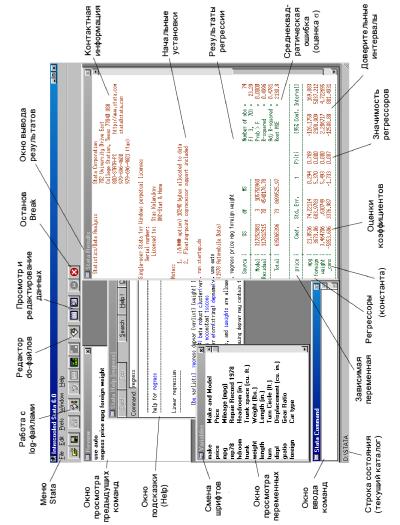
редактирования данных (Stata Editor), а также редактор программ (Stata Do-file Editor), Переключаться между окнами можно, тыкаясь мышкой в любое место на нужном окне, либо через меню Windows,
При вводе команд в окне Stata Command можно пользоваться стандартными средствами редактирования в Windows (выделения, стирания, вставки в буфер и из буфера). Можно вызывать предыдущие команды, нажимая PgUp и PgDn, и редактировать их (что очень полезно, сели при вводе команды были допущены мелкие опечатки, или если надо добавить какие-то опции или условия к предыдущей команде).
Можно менять кое-какие установки Stata в меню Prefs, например, сохранить текущие установки окон (размеры, положение, шрифты).
См, также: [GSW] , т.е, руководство Getting Started for Windows,
Обобщить: как выглядят команды Stata
Команды Stata, как правило, имеют следующий вид:
команда ісписок переменных] [if условие] [in диапазон] [using имя файлаі [[веса]], Іопции,]
Список переменных может состоять из одной переменной (например, если нужно получить сводные статистики или построить гистограмму), из двух (расчет корреляций или построение диаграммы рассеяния) и более (регрессии, графики со многими переменными), Условия if и in выделяют те наблюдения, для которых необходимо провести анализ (см, ниже параграф 3,6), Если команда предполагает работу с файлами (чтение, объединение и т,п,), то имя файла, с которым необходимо провести указанные действия, передается в конструкции using. Если разным наблюдениям необходимо придать разные веса, то для этого используется конструкция типа [weight-выражение! (см, help weights; квадратные скобки обязательны).
Наконец, дополнительные модификаторы и параметры, влияющие на выполнение команд Stata или вывод результатов, а также все, что не поместилось в упомянутые рамки синтаксиса, записываются в опции.
Есть несколько исключений из вышеупомянутого синтаксиса, в т,ч, команды, выполняющие повторные действия см, ниже параграф 3,11,
См, также: [U] 14 Language syntax
Узнать: помощь
В Windows-верии Stata для поиска нужной информации проще всего воспользоваться меню Help, в котором имеются подменю Search (поиск по ключевым словам, например, Durbin Watson statistic) и Stata Command (файл помощи по конкретной команде Stata), Впрочем, практически все то же самое можно сделать с клавиатуры командами search, help и whelp. Содержимое встроенной подсказки полностью дублируется в открытом доступе на сайте Stata: ,
Встроенная помощь Stata устроена гипертекстовым образом: если подвести мышку к фрагменту текста, выделенному зеленым цветом, то курсор превратится в ладошку, а если нажать при этом на левую кнопку мыши , то будет выведен соответствующий фрагмент подсказки Stata, Если зеленым цветом помечена ссылка в Internet, то Stata запустит внешний браузер (MS Internet Explorer, Netscape Navigator), В Stata 7 эти действия можно выполнять и с результатами, выводимыми в окно Results,
Полный список стандартных команд, входящих в состав начальной установки Stata, можно найти в меню Help/Contents (или по команде help contents). Эти команды сгруппированы по тематическим разделам: общее представление о пакете, синтаксис команд, работа с данными, графика, статистические средства, матричные команды, программирование, особенности работы в среде Windows,