
Дуброва Т. - Статистические методы прогнозирования в экономике
Московская финансово-промышленная академия
Введение
В настоящее время статистические методы прогнозирования заняли видное место в экономической практике. Широкому внедрению методов анализа и прогнозирования данных способствовало появление персональных компьютеров.
Распространение статистических программных пакетов позволило сделать доступными и наглядными многие методы обработки данных.
Все шире используются статистические методы прогнозирования в деятельности плановых, аналитических, маркетинговых отделов производственных предприятий и объединений, торговых, страховых компаний, банков, правительственных учреждений.
Теперь уже не требуется проводить вручную трудоемкие расчеты, строить таблицы и графики - всю эту черновую работу выполняет компьютер. Человеку же остается исследовательская, творческая работа: постановка задачи, выбор методов прогнозирования, оценка качества полученных моделей, интерпретация результатов.
Для этого необходимо иметь определенную подготовку в области статистических методов обработки данных и прогнозирования.
В данном учебном пособии в систематизированном виде изложены статистические методы анализа одномерных временных рядов и прогнозирования. Для изучения выбраны наиболее часто применяемые в экономической практике методы.
Большое внимание уделяется анализу полученных результатов.
Структура изложения соответствует логической
последовательности основных этапов анализа и прогнозирования временных рядов. Последний раздел посвящен развивающемуся направлению статистических исследований - прогнозированию временных рядов с помощью адаптивных моделей.
Глава 1. Классификация экономических прогнозов.
Требования, предъявляемые к временным рядам, и их компонентный состав
§ 1.1. Классификация экономических прогнозов
В современных условиях управляющие решения должны приниматься лишь на основе тщательного анализа имеющейся информации. Например, банк или совет директоров корпорации примет решение о вложении денег в какой-то проект лишь после тщательных расчетов, связанных с прогнозами состояния рынка, с определением рентабельности вложений и с оценками возможных рисков.
В противном случае могут опередить конкуренты, умеющие лучше оценивать и прогнозировать перспективы развития.
Для решения подобных задач, связанных с анализом данных при наличии случайных воздействий, предназначен мощный аппарат прикладной статистики, составной частью которого являются статистические методы прогнозирования. Эти методы позволяют выявлять закономерности на фоне случайностей, делать обоснованные прогнозы и оценивать вероятность их выполнения.
Под прогнозом понимается научно обоснованное описание возможных состояний объектов в будущем, а также альтернативных путей и сроков достижения этого состояния. Процесс разработки прогнозов называется прогнозированием (от греч. prognosis-предвидение, предсказание).
Прогнозирование должно отвечать на два вопроса:
- Что вероятнее всего ожидать в будущем?
- Каким образом нужно изменить условия, чтобы достичь заданного, конечного состояния прогнозируемого объекта?
Прогнозы, отвечающие на вопросы первого типа, называются поисковыми, второго типа - нормативными. Например, ставится задача обеспечить каждую семью отдельной квартирой с улучшенной планировкой.
Нормативные прогнозы продемонстрируют при каких капиталовложениях и к какому сроку возможно выполнение поставленной задачи.
В зависимости от объектов прогнозирования принято разделять прогнозы на научно-технические, экономические, социальные, военнополитические и т.д. Однако такая классификация носит условный характер, т.к. между этими прогнозами, как правило, существует множество прямых и обратных связей.
Классификация экономических прогнозов показана на рисунке 1.1. В зависимости от масштабности объекта прогнозирования экономические прогнозы могут охватывать все уровни: от микроуровня (рассматривающего прогнозы развития отдельных предприятий, производств и т.д.) до макроуровня (анализирующего экономическое развитие в масштабе страны) или - до глобального уровня (где существующие закономерности рассматриваются в мировом масштабе).
Важной характеристикой является время упреждения прогноза -отрезок времени от момента, для которого имеются последние статистические данные об изучаемом объекте, до момента, к которому относится прогноз.
По времени упреждения экономические прогнозы делятся на:
- оперативные (с периодом упреждения до одного месяца),
- краткосрочные (период упреждения- от одного, нескольких месяцев до года),
- среднесрочные (период упреждения более 1 года, но не превышает 5 лет),
- долгосрочные (с периодом упреждения более 5 лет).
Наибольший практический интерес, безусловно, представляют краткосрочные и оперативные прогнозы.
Прогнозирование экономических явлений и процессов включает в себя следующие этапы:
1. постановка задачи и сбор необходимой информации;
2. первичная обработка исходных данных;
3. определение круга возможных моделей прогнозирования;
4. оценка параметров моделей;
5. исследование качества выбранных моделей, адекватности их реальному процессу. Выбор лучшей из моделей;
6. построение прогноза;
7. содержательный анализ полученного прогноза.
§ 1.2. Виды временных рядов. Требования, предъявляемые к исходной информации
Статистическое описание развития экономических процессов во времени осуществляется с помощью временных рядов.
Временным рядом называется ряд наблюдений за значениями некоторого показателя (признака), упорядоченный в хронологической последовательности, т.е. в порядке возрастания переменной t-временного параметра. Отдельные наблюдения временного ряда называются уровнями этого ряда.
Временные ряды делятся на моментные и интервальные. В моментных временных рядах уровни характеризуют значения показателя по состоянию на определенные моменты времени. Например, моментными являются временные ряды цен на определенные виды товаров, временные ряды курсов акций, уровни которых фиксируются для конкретных чисел.
Примерами моментных временных рядов могут служить также ряды численности населения или стоимости основных фондов, т.к. значения уровней этих рядов определяются ежегодно на одно и то же число.
В интервальных рядах уровни характеризуют значение показателя за определенные интервалы (периоды) времени. Примерами рядов этого типа могут служить временные ряды производства продукции в натуральном или стоимостном выражении за месяц, квартал, год и т.д.
Иногда уровни ряда представляют собой не непосредственно наблюдаемые значения, а производные величины: средние или относительные. Такие ряды называются производными.
Уровни таких временных рядов получаются с помощью некоторых вычислений на основе непосредственно наблюдаемых показателей. Примерами таких рядов могут служить ряды среднесуточного производства основных видов промышленной продукции или ряды индексов цен.
Уровни ряда могут принимать детерминированные или случайные значения. Примером ряда с детерминированными значениями уровней служит ряд последовательных данных о количестве дней в месяцах. Естественно, анализу, а в дальнейшем и прогнозированию, подвергаются ряды со случайными значениями уровней.
В таких рядах каждый уровень может рассматриваться как реализация случайной величины - дискретной или непрерывной.
В таблице 1.1. приведены примеры временных рядов: первый ряд является моментным; второй ряд - интервальны. Уровни третьего временного ряда - расчетные величины, а сам временной ряд месячной динамики является производным.
Таблица 1.1.
| Примеры временных рядов | ||||||||||||||||||||||
|
| II) Фонд заработной платы работников предприятия (тыс. руб.) | ||
| Месяц | t | yt |
| Январь | 1 | 79,5 |
| Февраль | 2 | 84,1 |
| Март | 3 | 85,5 |
| Апрель | 4 | 88,5 |
| Май | 5 | 89,9 |
| Июнь | 6 | 90,0 |
| III) Среднесуточное производство продукции на предприятии (шт.) | ||
| Месяц | t | yt |
| Январь | 1 | 1570 |
| Февраль | 2 | 1590 |
| Март | 3 | 1595 |
| Апрель | 4 | 1603 |
| Май | 5 | 1610 |
| Июнь | 6 | 1600 |
Информация может также оказаться слишком короткой для использования некоторых методов анализа и прогнозирования динамики, предъявляющих жесткие требования к длине рядов. В то же время, слишком малые интервалы между наблюдениями увеличивают объем вычислений, а также могут приводить к появлению ненужных деталей в динамике процесса, засоряющих общую тенденцию.
Безусловно, вопрос о выборе интервала времени между уровнями ряда должен решаться исходя из целей каждого конкретного исследования.
Процесс прогнозирования экономических временных рядов базируется на выявлении закономерностей, объясняющих динамику процесса в прошлом, и использовании этих закономерностей для описания развития в будущем.
При этом проведение анализа развития и прогнозирования, как правило, опирается на математический аппарат, предъявляющий определенные требования к исходной информации.
Одним из важнейших условий, необходимых для правильного отражения временным рядом реального процесса развития, является сопоставимость уровней ряда. Для несопоставимых величин неправомерно проводить исследование динамики. Появление несопоставимых уровней может быть вызвано разными причинами: изменением методики расчета показателя, изменением классификаций, терминологии и т.д. Например, уровни временного ряда, характеризующие количество малых предприятий, могут оказаться несопоставимыми из-за изменения самого понятия малое предприятие.
Подразумевается, что это понятие должно быть одинаковым для всего исследуемого периода. Чаще всего несопоставимость встречается в стоимостных показателях, что вызвано изменением цен в анализируемом периоде.
Несопоставимость может возникнуть вследствие территориальных изменений, например, как результат изменения границ области, района, страны. Другой причиной несопоставимости являются структурные изменения, например, укрупнение нескольких ведомств путем слияния их в единое целое, или укрупнение производства за счет слияния нескольких предприятий в одно объединение.
В большинстве случаев удается устранить несопоставимость, вызванную указанными причинами, путем пересчета более ранних значений показателей с помощью формальных методов. Хотя далеко не всегда проведение такой обработки обеспечивает требуемую точность, что может привести к снижению ценности исходной информации, а, следовательно, и к затруднению дальнейшего анализа.
Для успешного изучения динамики процесса важно, чтобы информация была полной, временной ряд имел достаточную длину. Например, при изучении сезонных колебаний на базе месячных или квартальных данных желательно иметь информацию не менее, чем за 3 года.
Применение определенного математического аппарата также накладывает ограничение на допустимую длину временных рядов. Например, для использования регрессионного анализа требуется иметь временные ряды, длина которых в несколько раз превосходит количество независимых переменных.
Временные ряды не должны иметь пропущенные наблюдения. Пропуски могут объясняться как недостатками при сборе информации, так и происходившими изменениями в системе отчетности, в системе фиксирования данных. Например, изменяется круг основных видов промышленной продукции, данные о производстве которых собираются на базе срочной отчетности.
Решение об исключении какого-то показателя может быть отменено через некоторое время, в связи с тем, что становится очевидной его важность для аналитических исследований. В этом случае для использования этого временного ряда в дальнейшем анализе необходимо восстановить пропущенные уровни одним из известных способов восстановления пропусков (выбор метода зависит от специфики конкретного временного ряда).
Если же в систему показателей включен новый признак, учет которого не проводился ранее, то необходимо подождать, пока ряд достигнет требуемой длины или попытаться восстановить прежние значения косвенными методами (через другие показатели), если такой путь представляется возможным.
Уровни временных рядов могут содержать аномальные значения или "выбросы. Часто появление таких значений может быть вызвано ошибками при сборе, записи и передаче информации. Возможными источниками появления ошибочных значений являются: сдвиг запятой при перенесении информации из документа, занесение данных в другую графу и т. д.
Выявление, исключение таких значений, замена их истинными или расчетными является необходимым этапом первичной обработки данных, т.к. применение математических методов к засоренной информации приводит к искажению результатов анализа. Однако, аномальные значения могут отражать реальное развитие процесса, например, скачок курса доллара в черный вторник.
Как правило, эти значения также заменяются расчетными при построении моделей, но учитываются при расчете возможной величины отклонений фактических значений от полученных по модели.
Соответствие исходной информации всем указанным требованиям проверяется на этапе предварительного анализа временных рядов. Лишь после этого переходят к расчету и анализу основных показателей динамики развития, построению моделей прогнозирования, получению прогнозных оценок.
§ 1.3. Компоненты временных рядов. Проверка гипотезы о существовании тенденции
В практике прогнозирования принято считать, что значения уровней временных рядов экономических показателей состоят из следующих компонент: тренда, сезонной, циклической и случайной составляющих.
Под трендом понимают изменение, определяющее общее направление развития, основную тенденцию временного ряда. Это систематическая составляющая долговременного действия.
Наряду с долговременными тенденциями во временных рядах экономических процессов часто имеют место более или менее регулярные колебания - периодические составляющие рядов динамики.
Если период колебаний не превышает 1 года, то их называют сезонными. Чаще всего причиной их возникновения считаются природно-климатические условия.
Иногда причины сезонных колебаний имеют социальный характер, например, увеличение закупок в предпраздничный период, увеличение платежей в конце квартала и т.д.
При большем периоде колебания, считают, что во временных рядах имеет место циклическая составляющая. Примерами могут служить демографические, инвестиционные и другие циклы.
Если из временного ряда удалить тренд и периодические составляющие, то останется нерегулярная компонента.
Экономисты разделяют факторы, под действием которых формируется нерегулярная компонента, на 2 вида:
- факторы резкого, внезапного действия;
- текущие факторы.
Первый тип факторов (например, стихийные бедствия, эпидемии и др.), как правило, вызывает более значительные отклонения по сравнению со случайными колебаниями- иногда такие отклонения называют катастрофическими колебаниями.
Факторы второго типа вызывают случайные колебания, являющиеся результатом действия большого числа побочных причин. Влияние каждого из текущих факторов незначительно, но ощущается их суммарное воздействие.
Если временной ряд представляется в виде суммы соответствующих компонент, то полученная модель носит название аддитивной (1.1), если в виде произведения - мультипликативной (1.2) или смешанного типа (1.3):
| Yt = ut + st + vt + et | (1.1), |
| Yt = ut x st x vt x et | (1.2), |
| Yt = ut x st x vt + et | (1.3), |
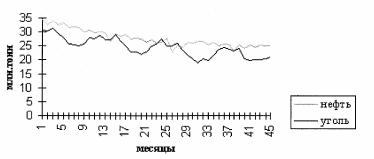
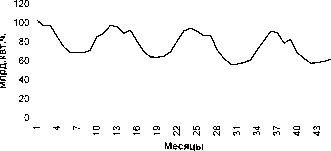
На рисунках 1.2, 1.3 приведены примеры временных рядов, иллюстрирующие присутствие в них указанных компонент. Графики месячных временных рядов производства промышленной продукции наглядно демонстрируют устойчивые сезонные колебания при снижающемся тренде, причем на последнем участке темпы падения производства заметно снижаются.
Решение любой задачи по анализу и прогнозированию временных рядов начинается с построения графика исследуемого показателя, тем более, что современные программные средства предоставляют пользователю большие возможности для этого. Не всегда при этом четко прослеживается присутствие тренда во временном ряду.
В этих случаях прежде, чем перейти к определению тенденции и выделению тренда, нужно выяснить, существует ли вообще тенденция в исследуемом процессе.
Основные подходы к решению этой задачи основаны на статистической проверке гипотез. Критерии выявления компонент ряда основаны на проверке гипотезы о случайности ряда.
Рассмотрим наиболее часто используемые на практике критерии проверки наличия-отсутствия тренда: критерий серий, основанный на медиане выборки и метод Фостера - Стюарта.
Критерий серий, основанный на медиане выборки, реализуется в виде следующей последовательности шагов:
1) Из исходного ряда yt длиной n образуется ранжированный (вариационный) ряд yt : y1, y^, ... , уП, где y1- наименьшее значение ряда yt .
2) Определяется медиана этого вариационного ряда Me. В случае нечетного значения n (n=2m+1) Me=y^ +1, в противном случае Me= (m + ym+1 )2.
3) Образуется последовательность Si из плюсов и минусов по следующему правилу:
+, если yt Me, t = 1, 2, ... ,n -, если yt Me, t = 1, 2, ... , n
(1.4.)
Если значение yt равно медиане, то это значение пропускается.
4) Подсчитывается v(n) -число серий в совокупности б,, где под серией понимается последовательность подряд идущих плюсов или минусов. Один плюс или один минус тоже будет считаться серией.
Определяется Tmax(n)- протяженность самой длинной серии.
5) Проверка гипотезы основывается на том, что при условии случайности ряда (при отсутствии систематической составляющей) протяженность самой длинной серии не должна быть слишком большой, а общее число серий - слишком маленьким. Поэтому для того, чтобы не была отвергнута гипотеза о случайности исходного ряда (об отсутствии систематической составляющей) должны выполняться следующие неравенства (для 5% уровня значимости).
Если хотя бы одно из неравенств нарушается, то гипотеза об отсутствии тренда отвергается.
Квадратные скобки в правой части неравенства означают целую часть числа. Напомним, что целая часть числа A - [A] - это целое число, ближайшее к А и не превосходящее его.
Другой способ проверки гипотезы о наличии тенденции процесса основывается на методе Фостера-Стюарта. Этот метод может быть реализован в виде следующей последовательности шагов:
1) Каждый уровень ряда сравнивается со всеми предшествующими, при этом определяются значения вспомогательных характеристик mt и lt:
1 если Yt Yt-i Уt-2’ - - - . Уі 0, в противном случае
(1.6.)
mt
Таким образом, mt=1, если yt больше всех предшествующих уровней, а1=1, если yt меньше всех предшествующих уровней.
2) Вычисляется dt=mt-lt для всех t=2^n.
Очевидно, что величина dt может принимать значения 0; 1; -1.
П
3) Находится характеристика D = ^dt.
t =2
4) С помощью критерия Стьюдента проверяется гипотеза о том, что можно считать случайной разность D-0 (т.е. ряд можно считать случайным, не содержащим тренд).
этого определяется:
= d
Для
G D
где gd- средняя квадратическая ошибка величины D:
л/2 ln n - 0,8456
2Z
GD =
t
Значения gd затабулированы.
| Таблица 1.2.Значения стандартных ошибок для gd для n от 10 до 100 | ||||||||||||||||||||||||||||||||||||||||||||||||
|
Пример 1.1.
Изменения курса акций промышленной компании в течение месяца представлены в таблице:
| Курс акций (дол.) | ||||||||||||||||||||||||||||||||||||||||||||||||
|
а) с помощью метода Фостера - Стюарта;
б) используя критерий серии, основанный на медиане выборки. Доверительную вероятность принять равной 0,95.
Решение:
а) Вспомогательные вычисления по методу Фостера- Стюарта представлены в таблице 1.3.
1) Если уровень yt больше всех предшествующих уровней, то в графе mt ставим 1, если yt меньше всех предшествующих уровней, то ставим 1 в графе lt;
2) Определяем dt=mt-lt для t=2^20;
20
3) D = ? d,= 3;
t=2
4) Значение а D для n=20 берем из таблицы 1.2. а d =2,279.
Значение tRF берем из таблицы t- распределения Стьюдента: t^ (а=0,05; К=19)=2,093; tH = = 1,316.
aD
^ нет оснований отвергнуть гипотезу об отсутствии тренда.
С вероятностью 0,95 тренд во временном ряду отсутствует.
Таблица 1.3.
Вспомогательные вычисления по методу Фостера-Стюарта
| t | yt | mt | et | dt | t | yt | mt | et | dt |
| 1 | 509 | - | - | - | 11 | 517 | 0 | 0 | 0 |
| 2 | 507 | 0 | 1 | -1 | 12 | 524 | 1 | 0 | 1 |
| 3 | 508 | 0 | 0 | 0 | 13 | 526 | 1 | 0 | 1 |
| 4 | 509 | 0 | 0 | 0 | 14 | 519 | 0 | 0 | 0 |
| 5 | 518 | 1 | 0 | 1 | 15 | 514 | 0 | 0 | 0 |
| 6 | 515 | 0 | 0 | 0 | 16 | 510 | 0 | 0 | 0 |
| 7 | 520 | 1 | 0 | 1 | 17 | 516 | 0 | 0 | 0 |
| 8 | 519 | 0 | 0 | 0 | 18 | 518 | 0 | 0 | 0 |
| 9 | 512 | 0 | 0 | 0 | 19 | 524 | 0 | 0 | 0 |
| 511 | 0 | 0 | 0 | 20 | 221 | 0 | 0 | 0 |
Таблица 1.4.
| Вспомогательные вычисления для критерия серии | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1) От исходного ряда yt переходим к ранжированному у[, расположив |
2) Т. к. n=20 (четное) ^ медиана Me = Уі0 +Уі1 = 516,5;
3) Значение каждого уровня исходного ряда yt сравнивается со значением медианы. Если yt Me, то 8і принимает значение +, если меньше, то-;