
СИНТЕЗ ОПТИМАЛЬНОГО КОМПЛЕКСА МЕХАНИЗМОВ УПРАВЛЕНИЯ
Очевидно, в управлении ОП наиболее существенны первый и третий типы самоорганизации (так как гомеостазис, как правило, характерен для процессной, а не проектной деятельности).
Так как отличительной чертой управления ОП является саморазвитие, то обсудим, что понимается под развитием. Общее определение [110, С. 561] таково: развитие - необратимое, направленное, закономерное изменение материальных и идеальных объектов.
Обратимость изменений имеет место в процессах функционирования (циклического воспроизведения постоянного набора функций)
Отсутствие закономерности характерно, например, для случайных процессов катастрофического типа, и имеет место, в частности, при последовательности рефлекторных управлений. В управлении ОП (да и любыми проектами) управление как воздействие на управляемую систему, производимое с целью обеспечения
требуемого ее поведения, непременно подчинено цели и носит закономерный характер.
При отсутствии направленности изменения не могут накапливаться и процесс теряет целостность. Следовательно, в управлении ОП существенно научение, так как подчиненность цели (порождающей критерий эффективности деятельности) дает возможность накапливать опыт и закреплять положительные изменения.
С точки зрения процессов развития в результате реализации ОП ОС переходит в качественно новое состояние - в ней возникают, трансформируются или исчезают элементы, связи, функции и т.д.
Введя основные определения, рассмотрим две теоретикоигровые модели саморазвития в управлении ОП.
Модель 1. Рассмотрим модель ОС - многоэлементную детерминированную двухуровневую активную систему (АС), состоящую из центра и п активных элементов (АЭ). Стратегией АЭ является выбор действий, стратегией центра - выбор функции стимулирования, то есть зависимости вознаграждения каждого АЭ от его действий и, быть может, действий других АЭ или других агрегированных показателей их совместной деятельности.
Обозначим yi е Ai - действие i-го АЭ, i е I = {1, 2, п} -
п
множество АЭ, y = (y1t y2, yn) е A' = П Ai - вектор действий
i=1
АЭ, y_i = (yi, У2, Уг-1, У1+1, ¦¦¦, Уп) е А_г = П Aj - обстановка игры
J
для i-го АЭ.
Предположим, что i-ый АЭ характеризуется параметром ri е Д, называемым его типом и отражающим эффективность деятельности АЭ, i е I. Вектор типов всех АЭ обозначим r = (r 1, Г2, Гп).
Пусть результат деятельности z е A0 = Q(A’, а) АС, a 0, состоящей из п АЭ, является функцией (называемой функцией агрегирования) их действий: z = Q(y, а), где а - параметр, отражающий технологию деятельности и характеризующий центр. Интересы и предпочтения участников АС - центра и АЭ - выражены их целевыми функциями. Целевая функция центра является функционалом фо, z) и представляет собой разность между его доходом 1 z, где 1 может интерпретироваться как рыночная цена, и суммарным вознаграждением u(z, r), выплачиваемым АЭ:
u(z, r) = 2 Si (z, r),
i=1
где Oi(z, r) - стимулирование i-го АЭ,
o(z, r) = (ol(z, r), o2(z, r), on(z, r)), то есть
(1) Ф(о(-), z, l r) = lz - ^Ог (z,r).
i=1
Целевая функция i-го АЭ является функционалом fi(ог, уг, ri) и представляет собой разность между стимулированием, получаемым им от центра, и затратами ci(yi, ri), где ri е Wi с - тип АЭ, то есть:
(2) fi(s(-), z, y, r) = Oi(z, r) - Ci(y, ri), i е I.
Отметим, что индивидуальное вознаграждение i-го АЭ в общем случае явным или неявным образом зависит от действий и типов всех АЭ (случай сильно связанных АЭ [90]).
Примем следующий порядок функционирования АС. Центру и АЭ на момент принятия решения о выбираемых стратегиях (соответственно - функциях стимулирования и действиях) известны целевые функции и допустимые множества всех участников АС, а также функция агрегирования.
Центр, обладая правом первого хода, выбирает функции стимулирования и сообщает их АЭ, после чего АЭ при известных функциях стимулирования выбирают действия, максимизирующие их целевые функции.
Рассмотрим случай, когда центр наблюдает только результат деятельности АС, от которого зависит его доход, но не знает и не может восстановить индивидуальных действий АЭ, то есть, имеет место агрегирование информации - центр имеет не всю информацию о действиях АЭ, а ему известен лишь некоторый их агрегат.
Обозначим Р(о) - множество реализуемых (выбираемых АЭ при данной системе стимулирования) действий. Минимальными затратами центра на стимулирование по реализации действий АЭ у’ е A’ будем называть минимальное значение суммарных выплат элементам, при которых данный вектор действий является равновесием Нэша в игре АЭ, то есть решение следующей задачи: min , где x(y’) = {о() I y’ e P(o)}. Как и в
? о i (Q( y',a), r) ®
s (¦)= (У)
одноэлементной АС [86], гарантированной эффективностью (далее просто эффективностью) стимулирования является минимальное значение целевой функции центра на соответствующем множестве решений игры (всюду, где встречаются минимумы и максимумы, будем предполагать, что они достигаются):
(3) К(о(-), l, a, r) = min Ф(о(-), Q(y, a), l r).
yeP(a (¦))
Задача синтеза оптимальной функции стимулирования заключается в поиске допустимой системы стимулирования о , имеющей максимальную эффективность:
(4) о*(1, a r) = arg max K(o(-), l, a, r).
о (¦)
В [90] доказано, что в частном случае, когда действия АЭ наблюдаются центром, и типы АЭ также достоверно известны центру,
П
оптимальной (точнее - ^-оптимальной, где 8 = ? 8г ) является
г=1
квазикомпенсаторная система стимулирования о K , зависящая от наблюдаемых действий АЭ:
Сг (У , Гі ) + 8 г , Уг = Уг
. 0, Уг * Уг*
i e I,
(5) О гк
где 8г - сколь угодно малые строго положительные константы, і e I, а оптимальное действие У , реализуемое системой стимулирования (5) как единственное равновесие в доминантных стратегиях (РДС) [48], является решением следующей задачи оптимального согласованного планирования [27]:
У*(г) = arg max {H (у) - ? ег (У, rt)},
У^А' id
где H (¦) - функция дохода центра, зависящая от наблюдаемых действий АЭ.
Определим множество векторов действий АЭ, приводящих к заданному результату деятельности АС:
Y(z, a) = {y e A’ | Q(y, a) = z} c A’, z e A0.
В [90] доказано, что в случае наблюдаемых действий и типов АЭ минимальные затраты центра на стимулирование по реализации вектора действий y е A’ равны суммарным затратам АЭ V ci (y, ri) . По аналогии вычислим: минимальные суммарные
І?І
затраты АЭ по достижению результата деятельности z е А0
П
J (z, a, r) = min V ci(y, ri), а также множество действий
yGY (z ,a) i=i
n
Y (z, a, r) = Arg min V ci(y, ri), на котором достигается соот-
yGY (z ,a) i=i
ветствующий минимум.
Введем относительно параметров АС следующие предположения, которые, если не оговорено особо, будем считать выполненными в ходе всего последующего изложения материала настоящего раздела:
А.1. i е I Ai - отрезок с левым концом в нуле.
А.2. i е I 1) функция ci(-) непрерывна по всем переменным; 2) yi е Ai, ri е Wi ci(yi, ri) неотрицательна и не убывает по yi и не возрастает по ri, i е I; 3) ri е Wi ci(0, ri) = 0, i е I.
А.3. Функции стимулирования принимают неотрицательные значения.
А.4. Q: A’x ® А0 с Жm - однозначное непрерывное отображение, где 1 ? m ? n.
А.5. x е А0 a 0 y’ е Y(x, a), i е I, yi е Proji Y(x, a) cj(y„ y’-i) не убывает по yt, j е I.
Фиксируем произвольный результат деятельности x е A0 и произвольный векторy*(x, a, r) е Y*(x, a, r) c Y(x, a).
Утверждение 1. При использовании центром следующей S-оптимальной системы стимулирования
(6) s * (z, a, r)
c(y \x,a,r), r) + , z = x . ,
, i е I,
0, z ^ x вектор действий АЭ y (x, a, r) реализуется как единственное РДС с минимальными затратами центра на стимулирование равными J*(x, a, r).
Доказательство утверждения 1 практически повторяет доказательство теоремы 4.5.1 в [90] и опускается.
На втором шаге решения задачи стимулирования ищется наиболее выгодный для центра результат деятельности АС х (1 a, r) е А0 как решение задачи оптимального согласованного планирования:
(7) х*(1, a, r) = arg max [1 х - J*(x, a, r)].
хеАо
В [90] доказана теорема об идеальном агрегировании в моделях стимулирования, которая утверждает, что в случае, когда функция дохода центра зависит только от результата деятельности АС, эффективности стимулирования одинаковы как при использовании стимулирования АЭ за наблюдаемые действия, так и при стимулировании за агрегированный результат деятельности. Этот результат справедлив и в рассматриваемой модели при условии, что центру известны: цена 1, функции затрат агентов (то есть, параметры {r}) и технология производства а.
Подставляя (7) и J (х (1, a, r), а, г) в (1) получаем зависимость целевой функции центра (которую можно рассматривать как его прибыль) от параметров 1, a и r:
(8) F(1, a, r) = 1 х*(1, a r) - J*(x*(1, a r), a r).
Если параметр 1 интерпретируется как внешняя (экзогенно заданная) стоимость единицы результата деятельности АС, то, варьируя два оставшихся параметра - a и r, центр может оптимизировать свою прибыль, то есть, максимизировать выражение (8).
Таким образом, мы осуществили переход от микромодели (задачи синтеза оптимальной функции стимулирования), в которой описывалось взаимодействие центра с подчиненными ему АЭ, к макромодели, отражающей эффективность технологии деятельности сотрудников заданной квалификации в зависимости от внешних условий (см. выражение (8)). Другими словами, получена возможность рассматривать оптимизационные задачи, не акцентируя внимания на аспектах активности участника и задачах управления АЭ (отражаемыми в теоретико-игровых моделях стимулирования с агрегированием информации).
Понятно, что, как изменение технологии a, так и квалификации r (эффективности деятельности) сотрудников - АЭ - требует определенных затрат, которые будем описывать функциями ca(a1, a2) и cr(r1, r2), которые отражают затраты центра соответственно на изменение технологии с a1 0 на а2 0 и изменение типов с r1 е W на r2 е W.
Относительно функций затрат предположим следующее: если a2 a1, то ca(a1, a2) 0, если a2 a1, то ca(a1, a2) 0, если r2 r1, то cr(r1, r2) 0. Обозначим (a0, r0) - начальное состояние (до реализации ОП) АС.
Возникают следующие три (две частных и одна общая) задачи:
1. Задача развития персонала. При заданных 1, а и r0 определить r е W, максимизирующее целевую функцию центра (8) с учетом затрат на изменение квалификации персонала:
(9) F(1 a, r) - cr(ra r) ® max .
reQ
Решение этой задачи имеет вид r (1, a r0);
2. Задача развития центра (совершенствования технологии деятельности). При заданных 1, r и а0 определить а 0, максимизирующее целевую функцию центра (8) с учетом затрат на изменение технологии:
(10) F(1 a r) - c0(a0, а) ® max .
а 0
Решение этой задачи имеет вид a (1 a0, r);
3. Задача комплексного развития. При заданном начальном состоянии (о0, r0) определить конечное состояние (a 0, r е W), максимизирующее целевую функцию центра (8) с учетом затрат на изменение технологии и квалификации персонала:
(11) F(1, a r) - ca(a0, a) - c^, r) ® max .
reQ, a0
Решение этой задачи имеет вид (r*(1, a0, r0), a*(1, a0, r0)).
При известных зависимостях F(- ), ca(-), cr() задачи (9)-(11) являются стандартными оптимизационными задачами. Приведем пример их решения.
Пример 1. Пусть агенты имеют квадратичные функции затрат типа Кобба-Дугласа: ci(yi, ri) = yf /2ri, i е I, а оператор агрегирования Q(y, a) = a ^ уг .
ieI
Тогда y*(x, l r) = x r, / aR, где R = Уri,
ІЕІ
v*(z, a r) = x2 / 2 a R, x*(1, a r) = l a R, F(1 a, r) = l2 a2 R / 2
(отметим, что в рассматриваемом примере имеет место идеальное агрегирование).
Если cB(a0, a) = Ь exp {a- a0}, cr(r0, r) = gexp {r - r0}, то R = R0 + In (l2 a2 / 2 d), а a определяется из решения следующего трансцендентного уравнения (если условие второго порядка не выполнено, то на максимальную величину a необходимо накладывать ограничения): I2 a [R0 + ln (l2 a2/2 d)] = b exp {a- a0}. - 1
До сих пор мы рассматривали, фактически, статический случай, в котором решалась задача выбора конечного состояния при известном начальном (см. задачу комплексного развития выше), то есть процесс перехода от начального состояния к конечному не детализировался. В ОП во многих случаях существенным оказывается процесс перехода, поэтому сформулируем динамическую задачу комплексного развития.
Пусть имеются T периодов времени: t = 1, T, для которых известна (точно или в виде прогноза) последовательность цен {1t}t = 1, T . Известно также начальное состояние ОС (a0, r0). Требуется определить допустимые траектории развития персонала {rt е Wt}t = 1, T и изменения технологии {at 0}t =1, T, которые максимизируют суммарную дисконтированную (с коэффициентом g) полезность центра:
T
(12) У {F(1t, at, rt) - ca(aui, at) - Cr(rt_b r)} ® max .
7=1 {r^Wt ,at^}t=lj
Для решения задачи (12) может быть использован метод динамического программирования.
Модель 2. Рассмотрим АС с распределенным контролем (РК), включающую один АЭ, характеризуемый функцией затрат c(y, 5), у е A, s е S, и k центрами, характеризуемыми функциями дохода H,(y, rІ), где r, е W,, i е K = {1, 2, ..., k} - множеству центров. Целевая функция І-го центра имеет вид
(13) Ф,(о,(-), y, r) = Hi(y, r) - s,(y), i e K, а целевая функция АЭ:
(14) f(o(-), y, s) = У (y) - c(y, s),
isK
где s(-) = (Gi(-), Sn(-)).
Порядок функционирования таков - сначала центры одновременно и независимо выбирают свои стратегии - функции стимулирования, а затем при известных функциях стимулирования АЭ выбирает действие, максимизирующее его целевую функцию (14).
В [91] доказано, что при использовании центрами компенсаторных систем стимулирования существуют два режима взаимодействия центров (два типа равновесий их игры) - режим сотрудничества и режим конкуренции, причем последний неэффективен для системы в целом. Поэтому одной из основных задач управления АС РК является обеспечение режима сотрудничества центром. Введем следующие величины:
(15) Wi(s, Гг) = max {H(y, r) - c(y, s)}, i e K,
ysA
(16) x*(s, r) = arg max {У H(y, r) - c(y, s)},
ysA isK
где r = (rГ2, rn) e W = г ,
isK
(17) W*(s, r) = max {У H(y, r) - c(y, s)}.
ysA isK
По аналогии с [44, 47, 91] запишем область компромисса
(18) L*(r, s) = {l 0 | H(x*(s, r), ri) - li W(s, ri), i e K;
У l = c(x*(s, r), s)}.
isK
В соответствии с результатами, полученными в [44], режим сотрудничества имеет место тогда и только тогда, когда множество
(18) не пусто. Обозначим
(19) W* хS* = {(r, s) e W xS | L*(r, s) * 0}.
Пусть s0 e S и r0 e W - начальные параметры АС и известны затраты cs,r(s0, r0, s, r) по их изменению до значений s e S и r e W, соответственно. Тогда возможны две постановки задачи.
Первая задача, которую условно можно назвать задачей выбора направления развития, заключается в определении таких значений параметров участников АС из множества (19), при которых затраты на изменения минимальны:
(20) cs,r(so, го, s, r) ® min* * .
(s, Г)gQ xS
Второй задачей является задача оптимального развития, которая заключается в выборе таких значений параметров участников АС, при которых выигрыш АС в целом (с учетом затрат на изменения) максимален:
(21) W*(s, r) - Cs,r(so, го s, r) ® max .
(s, r) G QxS
Задачи (20) и (21) являются стандартными задачами условной оптимизации. Термины саморазвитие и самоорганизация применимы к ним, так как они должны решаться центрами или метацентром, то есть участниками рассматриваемой АС.
В заключение рассмотрения настоящей модели отметим, что все полученные результаты по аналогии с тем, как это делалось в [44], могут быть обобщены на случаи: нескольких агентов с векторными предпочтениями, векторных предпочтений центров, многоуровневых АС.
Результаты исследования двух приведенных в настоящем разделе моделей саморазвития в управлении ОП (см. также модели матричных структур управления в шестом разделе) позволяют говорить о существовании единого подхода к описанию эффектов саморазвития и самоорганизации (см. также модели обучения менеджеров проектов в [37]). Подход этот заключается в следующем: сначала описывается зависимость равновесного (в теоретикоигровом смысле) состояния АС от параметров центра и агентов, характеризующих их свойства, которые могут изменяться. Затем вводятся затраты на целенаправленное изменение этих параметров, и решается задача определения таких новых значений этих параметров (или траектории их изменения), которые максимизировали бы эффективность функционирования АС в будущем (или в процессе перехода из заданного начального состояния в конечное) с учетом затрат на переход.
Применение данного подхода к максимально широкому классу задач управления динамическими АС представляется перспективным направлением будущих исследований.
СИНТЕЗ ОПТИМАЛЬНОГО КОМПЛЕКСА МЕХАНИЗМОВ УПРАВЛЕНИЯ
Приведем постановку задачи синтеза оптимального комплекса механизмов управления ОС. Пусть ОС описывается набором (вектором) множества L= {1, 2, 1} переменных:
У = (уі, У2, ¦¦¦, yd е A = П 4 , где y, е A„ i е L, и существуют гло-
ieL
бальные ограничения A на комбинации переменных: у е A’ о A .
Под механизмом ы(-) е X будем понимать отображение множества Mu сL значений управляемых переменных во множество Ku сL значений управляющих переменных, то есть u: AMu ® AKu, где AMu = П Ai , AKu = П Ai . Будем считать, что множество X
ieMu ieKu
допустимых механизмов таково, что для любого механизма u(-) е х, выполнены глобальные ограничения, то есть
(1) X = {u(d I (yMu, yKu): yKu = u(yMu) ® (yMu, yKu) е ProjMuuKu(A )},
где yMu =(yj)j е Mu, yKu =(yj)j е Ku-
Введем S с X - подмножество множества допустимых механизмов, S е 2х - множеству всех подмножеств множества X. Обозначим Qs - множество всевозможных последовательностей элементов множества S, qs - произвольный элемент множества Qs. Множество S механизмов назовем непротиворечивым, если
(2) 0$qs е Qs: $ (u, v) е qs: Mu о Kv * 0.
Свойство непротиворечивости означает, что для данного набора механизмов не существует их последовательности, для которой нашлась бы переменная, которая была бы одновременно управляемой для первого механизма в этой последовательности и управляющей - для последнего.
Непротиворечивость множества механизмов порождает в ОС иерархию: множество параметров АС может быть упорядочено - на
нижнем уровне находятся параметры из множества Ls = L \ - Ku,
ueZ
на следующем уровне - параметры, которые являются управляющими по отношению к параметрам нижнего уровня, но управляе-
мыми для параметров, находящихся на более высоких уровнях иерархии, и т.д.
Поставим в соответствие /-му параметру АС активного агента, обладающего целевой функцией f: А ® Ж1, / е L.
При заданном комплексе механизмов S агенты из множества LS будут стремиться выбирать равновесные по Нэшу стратегии. Обозначим соответствующее множество равновесий Нэша
(3) EN(S) = {yLs е Als I / е Ls, yt е А/
fikyLS, u(yLZ)) f/(yLlIy/, U^LsIyi))}, где u(yLS) - действия, выбираемые агентами из множества - Ku
ueS
(эти действия при заданном комплексе механизмов определяются действиями, выбираемыми агентами из множества LS).
Пусть на множестве А ’ состояний системы задан функционал Ф(-): А ® Ж1, характеризующий эффективность ее функционирования. Задача синтеза оптимального комплекса механизмов может формулироваться следующим образом:
(4) min F(yLs u(yLs)) ® max ,
yLZeEN (S) Se2" ,(1),(2)
то есть требуется найти непротиворечивый и удовлетворяющий глобальным ограничениям (условия (2) и (1) соответственно) комплекс механизмов, обладающий максимальной гарантированной эффективностью.
Отметим, что при формулировке задачи (4) мы не учитывали явным образом интересы агентов из множества - Ku . Если пред-
ugS
положить, что каждый из них может самостоятельно выбирать определенные механизмы управления, то получим задачу, аналогичной задаче структурного синтеза, описанной в [29, 85].
На сегодняшний день общих методов решения задачи (4) или задачи структурного синтеза неизвестно. Поэтому на практике при синтезе комплекса механизмов либо решают задачу последовательного синтеза, либо согласовывают в рамках той или иной метамодели отдельные оптимальные механизмы управления.
В матричных структурах управления, характерных для проектно-ориентированных организаций [113, 120, 137], каждый из управляемых субъектов (агентов в терминах управления проектами, АЭ в терминах теории активных систем) может быть одновременно подчинен нескольким управляющим органам (центрам). В теории активных систем (АС) такие модели получили название активных систем с распределенным контролем (РК).
Специфика АС РК заключается в том, что в них возникает игра центров, равновесие в которой определяет окончательное управляющее воздействие на агентов.
В работах [44, 47, 91], посвященных изучению АС РК, предполагается, что все управляющие органы оказывают воздействие либо на одни и те же компоненты вектора действий агента, либо на различные, но содержательно схожие (например, объем работ, продолжительность рабочего времени и т.д.) компоненты. В то же время, специфика стимулирования в управлении организационными проектами [113] такова, что, не только предпочтения, но и ответственность, возможности воздействия и т.д. различных центров могут быть определены на различных компонентах векторов действий и параметров агента (последние могут отражать, например, его квалификацию).
Примером может служить взаимодействие руководителей проектов (РП) и функциональных руководителей (ФР, то есть руководителей подразделений, которым принадлежат агенты, например, по штатному расписанию).
Руководитель проекта, который использует агента как ресурс, заинтересован в результатах его деятельности и осуществляет стимулирование в зависимости от этих результатов. Функциональный руководитель получает от руководителя проекта (естественно, косвенным образом в силу принадлежности одной организации и/или в рамках договорных отношений) вознаграждение за результаты деятельности агента данной квалификации и стимулирует агента в зависимости от квалификации.
В рамках рассматриваемой ниже теоретико-игровой модели взаимодействия участников системы (агента, руководителя проекта и функционального руководителя) анализируются равновесные состояния и обосновывается роль вышестоящих органов (устанавливающих правила игры для участников нижележащих уровней), которые выбором параметров механизма управления могут согласовать (в определенной степени) интересы руководителя проекта и функционального руководителя, побуждая их, соответственно, эффективно управлять деятельностью агентов и повышать квалификацию подчиненных.
Рассмотрим АС, состоящую из трех участников: РП, ФР и агента (см. рисунок 6), имеющих соответственно следующие целевые функции:
(1) Ф(а() ad), y, r) = H(y) - a(y) - s0(y, r),
(2) Фо(ао(¦), h(-), y, r) = ady, r) - h(r) - co(r),
(3) f(a(¦), h() y, r) = a(y) + h(r) - c(y, r),
где H(y) - функция дохода РП; a(y), a0(y, r), h(r) - функции стимулирования, c(y, r) - функция затрат агента, c0(r) - функция затрат ФР, y е A - действие агента, r е W - тип агента, отражающий его квалификацию (эффективность деятельности).
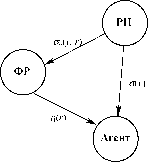
Содержательно, агент, подчиненный ФР, выбирает в рамках проекта, выполняемого под руководством РП, свой тип r е W и действие y е A. РП получает от выбора этого действия доход H(y) и
выплачивает агенту вознаграждение a(y), где a: A ® , а также
стимулирует ФР в размере a0(y, r), где a0: A х W ® , за использование подчиненного последнему агента. Вознаграждение агента складывается из стимулирования, получаемого от РП и зависящего от его действий, и стимулирования h(r), где h: W ® , получаемого от ФР и зависящего от его типа (квалификации).
Вторая составляющая оплаты может рассматриваться как тарифный оклад, не зависящий от действий. Затраты агента c(y, r) по выбору действия y е A зависят от его квалификации r е W.