
Туркин В. - Практикум - Методы обработки маркетинговой информации
Многие статические методы (кластерный анализ методом к-средних, проверка стат. гипотез, регрессионный анализ и другие) эффективно работают только при большом числе наблюдений. Действительно, пытаться оценить связь между факторами или даже рассчитывать среднюю при 10-20 наблюдениях не просто бессмысленно, но и вредно, т.к. полученные результаты будут иметь слишком большую погрешность. Маркетологу, если он не может собрать достаточного объема данных для количественного анализа, следует прибегнуть к качественным методам и содержательной оценки ситуации.
Таким образом, исходные данные для анализа - это большие базы данных (особенно в ритейл-аудите).
В пособие, как нам представляется, не целесообразно приводить, например, результаты опроса 500 респондентов по 30 вопросам с целью их дальнейшей обработки факторным анализом. Поэтому мы поступили следующим образом: те задачи, которые требуют больших объемов входных данных генерируются на компьютере.
Для этого мы предлагаем воспользоваться макросами (Excel), синтаксисом или скриптами (SPSS).
Изучение VBA (Visual Basic for Application), а также командного языка SPSS позволит вам сэкономить время и частично избавиться от нудной ручной работы, повторяющихся действий, которые может выполнить программа.
Для тех же заданий, где не требуется вводить слишком большие матрицы, исходные данные приведены в конечном виде.
Напоминаем, что для запуска
¦ синтаксиса в SPSS: FileNew^Syntax
¦ скрипта в SPSS: FileNew^-Script
¦ макроса в Excel: откройте редактор Visual Basic
В качестве комментария: в SPSS существует 2 способа управления с помощью команд: это скрипты и синтаксис. Спитаке - это язык макрокоманд, написанный специально для SPSS. Найти описание операторов можно в файле spssbase.pdf.
Скрипты пишутся на разновидности ?ВА, аналогичном тому, что используются в Excel. Помощь в освоении скриптов окажет 11.0 for Windows Developer's Guide.pdf , помещенная на сайте . Скрипты - это язык более продвинутый, чем синтаксис и он позволяет создавать несравненно более сложные вещи. Однако, непосредственно производить статистические расчеты с помощью скриптов невозможно. Создатели программы пошли следующим путем: из скриптов пользователь должен вызвать синтаксис, который непосредственно и запускает статистические расчеты.
Для этого используется следующая конструкция objSpssApp.ExecuteCommands strCommand , False, где в строковой переменной strCommand записан набор команд, который мы хотим выполнить. Т.о. с помощью скриптов мы формируем набор синтаксисов, который и позволяет осуществлять все необходимые действия.
Для успешного овладения предложенными методами обработки информации мы рекомендуем воспользоваться литературой, список которой приведен в конце пособия.
Также считаем необходимым подчеркнуть ту мысль, что обработка данных не является самоцелью, она всегда направлена на получение некоторой новой информации о рынке. Таким образом, после получения каких-то результатов по итогам анализа важно дать им содержательную интерпретацию.
Для этого с одной стороны нужно разбираться в статистических процедурах, а с другой - обладать знанием о процессах, проходящих на рынке, понимать психологию потребителя, разбираться в рекламе и продвижении товара, т.е. подходить к проблеме с позиции маркетинга. Специалист, опирающийся на достоверные количественные оценки, более объективно описывает ситуацию, что позволяет принимать обоснованные и эффективные решения.
Тема 1. ПОДГОТОВКА ДАННЫХ К АНАЛИЗУ Задание 1:
Подумайте, какой тип шкал наиболее подходит для кодирования ответов на следующие вопросы анкеты и создайте соответствующие переменные в SPSS с учетом шкалирования.
Исходная информация
A. Укажите Ваш возраст_
B. Семейное положение (замужем/незамужем)
C. Занятость (домохозяйка, пенсионерка, работает)
D. Укажите, согласны ли Вы со следующими утверждениями. Отражают ли они
| Ваши привычки И представления? (Отмечайте в соответствующих графах таблицы) | |||||||||||||||||||||||||||||||
|
| Признак | Рейтинг |
| проба | |
| оттенок золота | |
| художественная неповторимость | |
| место приобретения | |
| наличие ярлыка, скрепленного свинцовой пломбой | |
| размер, форма, стиль | |
| производитель | |
| страна производителя | |
| цена |
? цепочка
? браслет
? кольцо
? серьги
? запонка
? иное_
G. Укажите, в каком интервале находится ваш семейный доход из расчета на одного человека:
¦ 100-200$
¦ 200-400$
¦ 400-600$
¦ 600-800$
¦ 800-1000$
¦ 1000$
Задание 2:
В вашем распоряжении оказались данные об объемах сбыта. На этапе предварительного анализа выявите возможные выбросы. Для этого можно, например, исключить
все значения, выходящие за интервал т + 3 или воспользоваться иными критериями, упомянутыми в Пособии. Предварительно убедитесь, что случайная величина распределена нормально с помощью теста Колмогорова-Смирнова.
Исходная информация
С помощью представленного ниже синтаксиса сгенерируйте случайную величину, распределенную в соответствие с нормальным законом распределения N(0, =1), "загряз
ненную" другой случайной величиной, также распределенной нормально, но с дисперсией 3 =3.
Синтаксис SPSS
(обратите внимание, что в конце каждой строки должна стоять точка)
INPUT PROGRAM .
LOOP #i=l TO 500.
COMPUTE Sells = 5+rv. normal ( 0, 1 )*( 1-0.5)+rv.normal(0,3)*0.5 .
END CASE.
END LOOP.
END FILE .
END INPUT PROGRAM .
EXEC .
Таким образом Sells = r (1 )+ 2 , где j-ЛДОД), 2 ~ N(0,3). Степень "за
грязнения" можно регулировать с помощью коэф-та
Переменная Sells, - это смесь 2-нормальных случайных величин с разной дисперсией.
Задание 3:
Используя очищенные данные по сбыту из Задания 2 рассчитайте описательные статистики, а затем используйте опцию взвешивание из меню Данные (Data) для преобразование значений. Посмотрите, как изменятся статистики после взвешивания.
Для задания переменной весов вы можете воспользоваться меню Trans-form-^compute или синтаксисом.
Задание 4:
Проанализируйте представленные ниже данные о восприятии респондентами известной торговой марки по 3 параметрам, закодированным в переменных ?агі- ?агЗ. Выясните, существуют ли закономерности в распределении пропущенных данных.
Максимально точно восстановите пропущенные значения.
Исходная информация
_Скрипт SPSS_
Option Base 1 Sub Main()
Dim strMacrocall As String TotalNum=500 ' задали длину интервала R = 10
'доверительная вероятность для дисперсии t = l. 5
' задали размерность пространства Nvars = 3
' задали число центров кластеров NCentroids = Int(Rnd(l) *2+1)
' задали долю пропущенных значений Mrate=0.2
' Число наблюдений на кластер TotalClusterN=Int(TotalNum/NCentroids)
' CKO наблюдений вокруг центроидов StD=R/(2*(NCentroids+1)*t)
' генерируем координаты центров
Dim Centroid() As Single
ReDim Centroid(NCentroids, Nvars)
' создаем новый лист
objSpssApp.ExecuteCommands Input PROGRAM.vbCrLf, False For I = 1 To Nvars strMacrocall=
For k=l To NCentroids
' генерируем координату центроида Centroid(k, I)=Int(Rnd(1) *10+1)
' генерируем координаты точек вокруг центроида strMacrocall=strMacrocall+COMPUTE Var+LTrim(Str(I))+=RV.NORMAL(+LTrim(Str(Centroid(k,
I)))+,+LTrim(Str(StD))+).
strMacrocall=strMacrocall+vbCrLfEnd Case.+vbCrLf Next k
Call Plot(strMacrocall,TotalClusterN)
Next I
strMacrocall=
For I = 1 To Nvars
strMacrocall=strMacrocall+COMPUTE filter +Trim (Str(i))+=(uniform(1)=+Trim(Str(Mrate))+).SvbCrLf
strMacrocall=strMacrocall+If (filter+Trim(Str(i))+=l) var+Trim(Str(i))+=0.SvbCrLf
strMacrocall = strMacrocall + MISSING VALUES Var+Trim(Str(i))+(0).vbCrLf Next i
Call Missing(strMacrocall)
End Sub
Sub Plot(strMacrocall,Iterate)
Dim strCommand As String
strCommand = strCommand + set errors=off.vbCrLf strCommand = strCommand + Loop #i=l To +Trim(Str(Iterate))+.SvbCrLf strCommand = strCommand + strMacrocall strCommand = strCommand + End Loop.SvbCrLf strCommand = strCommand + End FILE.SvbCrLf strCommand = strCommand + End Input PROGRAM.vbCrLf strCommand = strCommand + EXEC.vbCrLf 'MsgBox strCommand
objSpssApp.ExecuteCommands strCommand , False End Sub
Sub Missing(strMacrocall) strCommand=strCommand+USE All.vbCrLf strCommand=strCommand+strMacrocall
strCommand=strCommand+If (filter_$=l) varl=0.vbCrLf strCommand = strCommand + Execute .vbCrLf objSpssApp.ExecuteCommands strCommand , False End Sub
Примечание: в теле скрипта код, начинающийся со знака ‘, не вызывает никаких действий, используется для пояснения текста и может быть опущен, например, строку V-енерируем координаты центров в теле программы можно не писать.
Приведенный выше синтаксис, как это легко убедиться генерирует определенные кластеры, а затем случайным образом убирает значения, поэтому пытаться строить регрессию здесь, видимо, не стоит. Хотя убедиться в отсутствии связи между пропущенными значениями и переменными будет полезно.
Тема 2. ПРЕДВАРИТЕЛЬНЫЙ АНАЛИЗ
Задание 1
По данным retail-audit произведите первичный анализ: рассчитайте меры центральной тенденции, вариацию, квартили цен, постройте гистограмму, коробчатую диаграмму, и обоснуйте гипотезу о виде распределении данной величины.
Исходная информация
| цена | цена | цена | цена | цена | |||||
| 1 | 32,14 | 21 | 26,55 | 41 | 23,13 | 61 | 31,91 | 81 | 29,1 |
| 2 | 22,4 | 22 | 29,5 | 42 | 26,18 | 62 | 27,32 | 82 | 26,53 |
| 3 | 25,05 | 23 | 34,5 | 43 | 25,72 | 63 | 25,1 | 83 | 26,24 |
| 4 | 27,79 | 24 | 28,22 | 44 | 26,25 | 64 | 32,14 | 84 | 33,42 |
| 5 | 27,72 | 25 | 37,74 | 45 | 25,65 | 65 | 29,4 | 85 | 39,23 |
| 6 | 31,35 | 26 | 29,41 | 46 | 27,3 | 66 | 27,17 | 86 | 26,39 |
| 7 | 24,7 | 27 | 31,84 | 47 | 30,36 | 67 | 26,83 | 87 | 28,94 |
| 8 | 29.68 | 28 | 30,61 | 48 | 36,37 | 68 | 27,74 | 88 | 33,06 |
| 9 | 31,95 | 29 | 27,18 | 49 | 25,21 | 69 | 27,04 | 89 | 27,3 |
| 10 | 28.18 | 30 | 28,93 | 50 | 24,71 | 70 | 27,74 | 90 | 29,78 |
| 11 | 29,39 | 31 | 25,9 | 51 | 30,87 | 71 | 31,43 | 91 | 25,96 |
| 12 | 31,6 | 32 | 34,03 | 52 | 24,47 | 72 | 24,44 | 92 | 28,68 |
| 13 | 27,12 | 33 | 33,66 | 53 | 26.88 | 73 | 26,6 | 93 | 29.82 |
| 14 | 32,01 | 34 | 26,42 | 54 | 30,69 | 74 | 26,09 | 94 | 28.3 |
| 15 | 35,29 | 35 | 23,95 | 55 | 29,53 | 75 | 31,08 | 95 | 27,99 |
| 16 | 27,11 | 36 | 29,51 | 56 | 26,04 | 76 | 31.68 | 96 | 23,68 |
| 17 | 24,04 | 37 | 33 | 57 | 29,44 | 77 | 33,44 | 97 | 29,74 |
| 18 | 24,34 | 38 | 24,61 | 58 | 24,6 | 78 | 29,14 | 98 | 27,99 |
| 19 | 31,59 | 39 | 27,99 | 59 | 26,21 | 79 | 22,53 | 99 | 28,09 |
| 20 | 32,5 | 40 | 37,09 | 60 | 25,44 | 80 | 36,85 | 100 | 26,08 |
Задание 2
Выясните зависимость между переменной ?агі и ?аг2 как при условии, что на них
влияет переменная ?агЗ, так и без этого условия.
_Исходная информация__
| Затраты на рекламу ?агі | Продажи ?аг2 |
Общие затраты на производство, дистрибуцию, рекламу. ?агЗ |
Затраты на рекламу ?агі | Продажи ?аг2 |
Общие затраты на производство, дистрибуцию, рекламу. ?агЗ |
||
| 1 | 37,5 | 4,1 | 7073,0 | 21 | 36,0 | 3,9 | 6793,3 |
| 2 | 36,1 | 4,1 | 7172,3 | 22 | 35,3 | 4,0 | 6841,1 |
| 3 | 37,2 | 3,9 | 6872,4 | 23 | 37,2 | 4,3 | 7420,7 |
| 4 | 35,7 | 3,8 | 6646,1 | 24 | 40,2 | 4,6 | 7926,7 |
| 5 | 38,5 | 4Д | 7498,0 | 25 | 36,2 | 3,9 | 6743,6 |
| 6 | 37,6 | 4,0 | 7060,1 | 26 | 39,1 | 4,4 | 7418,9 |
| 7 | 36,5 | 4Д | 6969,9 | 27 | 37,9 | 4Д | 7498,0 |
| 8 | 36,1 | 4,3 | 7194,4 | 28 | 37,7 | 4Д | 7306,6 |
| 9 | 38,2 | 4,3 | 7475,9 | 29 | 38,2 | 4,7 | 7963,5 |
| 10 | 40,1 | 4,3 | 7538,5 | 30 | 38,1 | 4,0 | 6973,6 |
| 11 | 40,7 | 4,4 | 7807,1 | 31 | 40,5 | 4,6 | 8147,5 |
| 12 | 40.8 | 4,4 | 7739,0 | 32 | 38,0 | 3,8 | 7089,5 |
| 13 | 40,0 | 4,5 | 7937,8 | 33 | 39,2 | 4,2 | 7518.2 |
| 14 | 36,2 | 4,0 | 7396.8 | 34 | 33,6 | 3,7 | 6383,0 |
| 15 | 38,2 | 4,1 | 7181,5 | 35 | 40,7 | 4,3 | 7947,0 |
| 16 | 39,0 | 4,1 | 7347,1 | 36 | 37,5 | 4,1 | 6901.8 |
| 17 | 39,7 | 4,3 | 7566,1 | 37 | 40,5 | 4Д | 7277,2 |
| 18 | 37,7 | 4,2 | 7323,2 | 38 | 39.8 | 4,5 | 7867,8 |
| 19 | 34,9 | 3,9 | 6911,0 | 39 | 38,5 | 4,3 | 7671,0 |
| 20 | 39,0 | 4Д | 7372,9 | 40 | 38,6 | 4,3 | 7361.8 |
Тема 3. АНАЛИЗ ТАБЛИЦ СОПРЯЖЕННОСТИ Задание 1
Постройте таблицу сопряженности для исходных данных, выявите зависимость между выбором респондентом магазина (переменная Shop содержит 3 вида торговых точек) и группой, к которой он принадлежит. Респонденты разделены по полу (переменная Gender , где 1 - мужчины, 2 - женщины, (переменная номинальная, а не ранговая)) и по возрасту (переменная Age: 25-35- код 1, 35-50 -код 2).
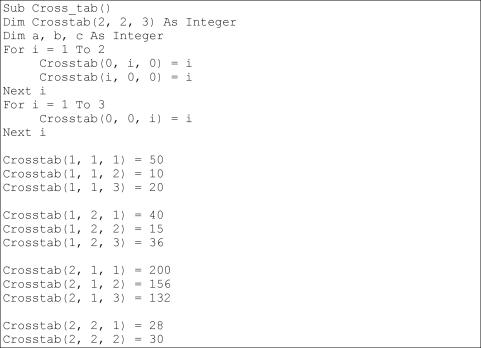
Crosstab(2, 2, 3) = 24
Cells(1, 1).Value = Gender Cells(1, 2).Value = Age Cells(1, 3).Value = Shop
LastN = 1 For i = 1 To 2
a = Crosstab(i, 0, 0)
For j = 1 To 2
b = Crosstab(0, j, 0)
For к = 1 To 3
Nij = Crosstab(i, j, k) c = Crosstab(0, 0, k)
| N = 1 То Cells(N | Nij + LastN, |
1) | .Value | = a |
| Cells(N | + LastN, | 2) | .Value | = b |
| Cells(N | + LastN, | 3) | .Value | = c |
LastN = LastN + Nij Next к Next j Next i End Sub
Задание 2
Исследуйте зависимость между полом и использованием Интернет. Постройте двухвходовую таблицу и воспользуйтесь мерами связанности для переменных с порядковой шкалой, используемых для квадратных таблиц.
Gender: 1 - мужчины 2 - женщины
Internet: 1 - использует мало 2 - использует много
| Исходная информация VBA Excel |
||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Тема 4. АНАЛИЗ МНОЖЕСТВЕННЫХ ОТВЕТОВ |
Задание 1
Постройте таблицу частот и таблицу сопряженностей для переменных, закодированных в дихотомическом виде. Данные представляют собой ответы мужчин и женщин на вопрос о марках пива, которые они потребляют.
Респонденту на выбор предложили 4 марки, он мог выбрать любое число потребляемых сортов.
Кодировка переменной Gender: 1- мужчины, 2 - женщины.
Исходная информация
VBA Excel
| Sub Response_() | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
| EndN = TotalN | |
| For i = 1 То 2 | |
| For j = 1 To | 4 |
| For N = StartN To EndN | |
| If Rnd(1 | ) Response(i, j) / TotalN Then Res = 1 Else Res |
| = 0 | |
| Cells(N, | 1).Value = i |
| Cells(N, | j + 1).Value = Res |
| Next N | |
| Next j | |
| StartN = StartN + TotalN | |
| EndN = EndN + | TotalN |
| Next i | |
| End Sub |
Задание 2
Подсчитайте таблицу частот для категориальных данных. В данном исследовании выбор респондентов ограничили 3 марками, которые были закодированы следующим образом
| 1 - Brand A, 2 - Brand B, 3 - Brand C, 4 - Brand D _Исходная информация___ |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Исходная информация
VBA Excel
Sub Categor()
Dim Response(1 To 4)
Response(1) = 30 Response(2) = 95 Response(3) = 160 Response(4) = 297
TotalN = Response(1) + Response(2) + Response(3) + Response(4)
'Перекодируем в вероятности
Response(1) = Response(1) / TotalN
Response(2) = Response(1) + Response(2) / TotalN
Response(3) = Response(2) + Response(3) / TotalN
For N = 1 To TotalN / 3
Dim Choice(1 To 3)
For k = 1 To 3 Do
Select Case Rnd(l)
Case Is = Response(1)
Choice(k) = 1
Case Response(1) To Response(2)
Choice(k) = 2
Case Response(2) To Response(3)
Choice(k) = 3 Case Is Response(3)
Choice(k) = 4 End Select Select Case k Case 1 Exit Do Case 2
If Choice(2) Choice(1) Then Exit Do Case 3
If Choice(3) Choice(1) And Choice(3) Choice(2) Then Exit Do End Select Loop
Cells(N, k).Value = Choice(k)
Next k Next N End Sub
Тема 5. ТЕСТИРОВАНИЕ СТАТИСТИЧЕСКИХ ГИПОТЕЗ: ВИД РАСПРЕДЕЛЕНИЯ И ПАРАМЕТРЫ
Задание 1
Обоснуйте гипотезу о типе распределения.
| VAR1 | VAR1 | VAR1 | VAR1 | VAR1 | |||||
| 1 | 18,93 | 21 | 88.63 | 41 | 83,15 | 61 | 29,05 | 81 | 54,35 |
| 2 | 81,26 | 22 | 33,63 | 42 | 148.12 | 62 | 32,45 | 82 | 49,64 |
| 3 | 48,34 | 23 | 43 | 43 | 45,19 | 63 | 23,89 | 83 | 44,83 |
| 4 | 58,34 | 24 | 146,11 | 44 | 47,83 | 64 | 69,14 | 84 | 51,45 |
| 5 | 55,87 | 25 | 35,25 | 45 | 86.82 | 65 | 19,38 | 85 | 149,24 |
| 6 | 100,47 | 26 | 46,34 | 46 | 39,32 | 66 | 24,04 | 86 | 56,69 |
| 7 | 72,4 | 27 | 55,97 | 47 | 58.62 | 67 | 105,21 | 87 | 168.43 |
| 8 | 61,77 | 28 | 68.17 | 48 | 10,14 | 68 | 85,8 | 88 | 47,13 |
| 9 | 20,69 | 29 | 41,66 | 49 | 127,85 | 69 | 35,35 | 89 | 51,63 |
| 10 | 47,28 | 30 | 42,3 | 50 | 88.9 | 70 | 111,31 | 90 | 54,82 |
| 11 | 65,41 | 31 | 57,2 | 51 | 29,5 | 71 | 76,62 | 91 | 56 |
| 12 | 60,1 | 32 | 55,17 | 52 | 82,3 | 72 | 99,24 | 92 | 44,02 |
| 13 | 24,99 | 33 | 44,61 | 53 | 24,46 | 73 | 29,73 | 93 | 28 |
| 14 | 37,47 | 34 | 49,48 | 54 | 85,71 | 74 | 86.35 | 94 | 27,41 |
| 15 | 72,23 | 35 | 39,14 | 55 | 37,18 | 75 | 43,01 | 95 | 86.59 |
| 16 | 179,52 | 36 | 103,04 | 56 | 35,09 | 76 | 55,37 | 96 | 115,18 |
| 17 | 87,51 | 37 | 34,81 | 57 | 42,17 | 77 | 52,35 | 97 | 58.1 |
| 18 | 54,58 | 38 | 27,51 | 58 | 57,56 | 78 | 60,61 | 98 | 17,93 |
| 19 | 43,23 | 39 | 75,02 | 59 | 33,42 | 79 | 92,02 | 99 | 63,43 |
| 20 | 19,61 | 40 | 54,04 | 60 | 49,64 | 80 | 97,72 | 100 | 47,12 |
Задание 2
Проверьте гипотезы о равенстве средних значению 10 млн. руб. отдельно по каждой переменной
Исходная информация
Исходные данные представляют собой информацию о продажах в торговых точках Reg 10 и Reg 11 - продажи в регионе 1 до и после проведенной рекламной компа
нии.
| Regl 0 | Regl 1 | Reg2 | Regl 0 | Regl 1 | Reg2 | ||
| 1 | 10,41 | 17,21 | 16,01 | 26 | 10,45 | 13,64 | 11,46 |
| 2 | 7,67 | 13,13 | 12,49 | 27 | 9,64 | 14,15 | 7,57 |
| 3 | 9.98 | 14,64 | 8,23 | 28 | 9,57 | 14,09 | 11,35 |
| 4 | 11,39 | 17,06 | 13,74 | 29 | 10,18 | 12.81 | 13.86 |
| 5 | 10,33 | 13,46 | 12.89 | 30 | 9,14 | 12,15 | 8,25 |
| 6 | 10.98 | 14,26 | 15.82 | 31 | 9,41 | 15,37 | 11,25 |
| 7 | 8,57 | 14,16 | П,7 | 32 | 10,97 | 13,62 | 8,84 |
| 8 | 9,29 | 14,53 | 11,18 | 33 | 9,95 | 13,38 | 11.68 |
| 9 | 10,36 | 13,39 | 9.89 | 34 | 10,44 | 15,47 | 11,41 |
| 10 | 9,5 | 15,73 | 14,13 | 35 | 10,01 | 13.81 | 10,93 |
| 11 | 8,98 | 14,32 | 7,36 | 36 | 10,96 | 15 | 13,44 |
| 12 | 8,38 | 15,44 | 9,65 | 37 | 8,95 | 13.88 | 12,44 |
| 13 | 9,27 | 14,43 | 10,42 | 38 | 10,42 | 13,52 | 9,73 |
| 14 | 11,27 | 15,29 | 17 | 39 | 9,07 | 12.83 | 9,87 |
| 15 | 9,19 | 15,5 | 10,74 | 40 | 11,41 | 15,7 | 9,36 |
| 16 | 8,69 | 14,03 | 11,05 | 41 | 9,34 | 12,07 | 14,97 |
| 17 | 9,47 | 13,87 | 12,43 | 42 | 10,73 | 13,45 | 9,07 |
| 18 | 8,42 | 11.82 | 8,39 | 43 | 11,03 | 14,63 | 10,4 |
| 19 | 11,32 | 12,63 | 9,59 | 44 | 8,82 | 13,82 | 13,92 |
| 20 | 9,02 | 15.18 | 10,16 | 45 | 11,27 | 14,56 | 12,74 |
| 21 | 9,48 | 15,2 | 9,93 | 46 | 11,62 | 14,68 | 11,76 |
| 22 | 8,35 | 14,68 | 9,01 | 47 | 10,23 | 16,31 | 12,09 |
| 23 | 9.18 | 14,57 | 10,19 | 48 | 10,19 | 13,68 | 15,02 |
| 24 | 8.88 | 12,94 | 13,77 | 49 | 9,24 | 14,64 | 10,6 |
| 25 | 10,85 | 12,48 | 8,64 | 50 | 11,03 | 14,79 | 10.81 |
Задание 3
Проверьте гипотезы о неизменности продаж в регионе 1 до и после рекламной компании.
Проверьте гипотезы о равенстве объемов продаж в регионе 1 и 2..
Задание 4
Проверьте указанные гипотезы, используя непараметрические статистики.
Тема 6. ДИСПЕРСИОННЫЙ АНАЛИЗ
Задание 1
Американский Театр, расположенный в Сан-Франциско решил провести исследование, направленное на улучшение планирования. Была разработана анкета, которую потом разослали по почте более 9000 постоянным посетителям (тем, кто приобрел абонементы).
Вернулось 982 анкеты. Все подписчики (переменная Subscr) были разделены на 6 групп в зависимости от продолжительности их абонемента: от постоянных подписчиков (на все ІОмесяцев) до случайных посетителей.
Также они были сегментированы по возрасту (Age), доходу (Income), культурной активности (CActiv).
Требуется выявить влияние сегментации на склонность посещать театры.
Исходная информация
Скрипт SPSS
Option Base 1 Sub Main
' общее число наблюдений TotalNum=982
Iterate=Int(TotalNum/(4*3*6)+0.5)
'флажок, равны средние (одинаковое значение факторов) или нет
If Rnd(l)0.5 Then Equal=0 Else Equal=l
'флажок, равны дисперсии или нет
If Rnd(l)0.5 Then Disp=0 Else Disp=l
Dim Age(4) As Single
Dim Income(3) As Single
Dim CActiv(6) As Single
Dim StDeviat(4,3,6)
' задаем значения факторов For i=l То 4
If Equal=l Then Age(i)=Rnd(1) Else Age(i)=0.5 Next i
For i=l To 3
If Equal=l Then Income(i)=Rnd(1) Else Income(i)=0.5 Next i
For i=l To 6
If Equal=l Then CActiv(i)=Rnd(1)Else CActiv(i)=0.5 Next i
' задаем значения дисперсий For i=l To 4 For j=l To 3 For k=l To 6
Select Case Disp Case 1
StDeviat(i,j,k)=Rnd(1)/10 Case 0
If Equal=0 Then StDeviat(i,j,k)=1 Else StDeviat (i, j,k)=0.1 End Select Next k Next j Next i
' создаем новый лист
objSpssApp.ExecuteCommands Input PROGRAM.SvbCrLf, False ' рассчитываем значения переменных For i=l To 4 For j=l To 3 For k=l To 6