
Содержание дифференциального алгоритма чтения
Обратимся вновь к рис. 11. Заключительные этапы преобразования фрагмента текста включают выделение значения из полученного смысла. Означает ли это, что всегда, в любом тексте есть все компоненты этой схемы?
Совсем нет. Однако содержание каждого ее элемента идет по убывающей.
В самом деле, тексты всегда содержат информацию. Немного можно найти бессмысленных текстов.
Но очень многие осмысленные тексты не содержат значения. В литературе по логике обычно приводят пример такого пустого выражения:
понятие, выраженное словами король Франции, имеет смысл, но применительно к XX в. значения не имеет. Возможны ли научные тексты подобного сдержания?
Для ответа достаточно узнать, есть ли значение в цитируемом тексте.
Рассмотрим некоторый тотальный и, следовательно, уникальный экземпляр А. Установление тождества экземпляра с самим собою можно рассматривать как отображение, приводящее образы А в соответствии с прообразом А. Экземпляр А по определению может быть сопоставлен только с самим собою. Поэтому отображение является внутренним и, согласно теореме Стилова, может быть представлено в виде суперпозиции топологического и последующего аналитического отображения.
Совокупность образов А составляет точечную систему, элементы которой являются эквивалентными точками ...
Как показал анализ, проведенный советским лингвистом И. П. Севбо, формальная связанность и наукообразное звучание не уменьшают пустоты этого текста.
Очевидно, теперь мы можем ответить на вопрос о том, что же следует читать в текстах: нужно уметь находить значение.
Как же практически научиться выделять значение? Рассмотрим еще одно интересное явление. Как показал Н. И. Жинкин, мозг каждого человека уже обладает этой способностью, так как содержит программу выделения значения в любом читаемом тексте, имеющем смысл.
Эксперименты психологов! подтвердили, .что при обработке текста человеческий мозг всегда выделяет ядерное значение независимо от способа его формального выражения или смысла. Так, в одном из опытов группе испытуемых предлагалось нажимать специальную кнопку каждый раз, как только на экране появлялось слово доктор, и не реагировать на сигнал, если появлялись другие слова, даже сходные по начертанию, например диктор. Большинство испытуемых справились с
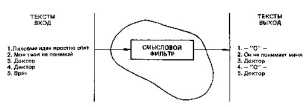
Рис. 12. Фильтрующая способность мозга
этим заданием. Затем без предупреждения на экране была показана надпись врач.
Практически все нажали кнопку, хотя по начертанию это слово никак не походило на слово доктор.
Этот пример — доказательство того, что при восприятии текстовой информации мозг реагирует не на языковую структуру слова, а на его содержательную часть. Восприятие мозгом различных словосочетаний показано на рис.
12. Благодаря наличию алгоритмического фильтра мозг не пропускает (выдает на выходе 0) фразу Лиловые идеи яростно спят.
Для фразы Моя твоя не понимай формируется соответствующее выражение. И наконец, мозг реагирует одинаково на слова врач и доктор, тогда как для слова диктор на выходе также 0.
Содержание дифференциального алгоритма чтения
При чтении текста мозг формирует свою трактовку содержания того, что читается. Происходит перекодирование сообщения на язык собственных мыслей читателя. Мозг выделяет ядерное, сущностное значение из текста. Однако не всегда эта программа используется эффективно.
Вместе с тем только при осмысленном, внимательном чтении текст понимается глубоко и полно. Из этого следует, что при обучении методам быстрого чтения учат произвольно использовать эту принципиально важную программу работы мозга.
Как показали эксперименты, знание и умелое применение некоторых упражнений дают возможность извлекать ядерное значение в тексте быстро и надежно. Эти упражнения основаны на использовании дифференциального алгоритма чтения. Он показан на рис. 13.
Центральное место в этом алгоритме занимает блок, который мы называем доминантой (это слово в переводе с латинского языка означает господствующий, основной, главный) . Что же такое доминанта применительно к тексту?
Ответом на этот вопрос может служить одно восточное предание. Персидский царь, большой любитель книг, имел обыкновение в поездках возить с собой библиотеку, нагруженную на сто верблюдов.
Однажды ему показалось это обременительным, и он поручил ста мудрым мужам сделать из этих книг извлечения, которые мог бы поднять один сильный мул. Вскоре, однако,
Рис. 13. Три блока дифференциального алгоритма чтения
царь приказал мудрецам составить новое извлечение, занимающее одну небольшую книгу, которую всегда можно иметь при себе. Наконец, и это показалось ему неудобным, и тогда снова собрались мудрые мужи. В итоге вместо
ста верблюжьих тюков получилось одно остроумное изречение, которое царь стал носить в своем сердце.
То, что вы прочитаете дальше, не заменяет всех наших бесед, а представляет лишь важнейшую их часть — доминанту:
Вы можете повысить скорость чтения в три раза, значительно улучшить качество усвоения прочитанного, развить мышление, внимание, память. Главное, вы научитесь работать так, что каждый раз при чтении текста мозг будет
экономно и точно отбирать полезное и нужное из потока воспринимаемой информации.
Мы привели здесь пример составления доминанты многих текстов всей нашей книги. Нужно научиться при чтении текста всегда формировать свою доминанту. Как показывают исследования психологов, при чтении текста мозг формирует свою трактовку содержания того, что читается. Происходит перекодирование сообщения на язык собственных мыслей читателя. Мозг выделяет ядерное, сущностное значение из текста.
Однако не всегда эта программа используется нами эффективно. Вместе с тем только при осмысленном, внимательном чтении текст понимается глубоко и полно.
Следовательно, при обучении методам быстрого чтения нужно научиться использовать эту принципиально важную программу работы мозга.
Знание и умелое применение некоторых упражнений дают возможность извлекать ядерное значение из текста быстро и надежно. Упражнения основаны на использовании дифференциального алгоритма чтения.
Сделаем наше первое открытие: что это такое?
Открытие, обсуждаемое здесь, состоит в том, что, оказывается, хорошие читатели читают ради понимания смысла, охватывают с одного взгляда много слов сразу, в то время как плохие читатели читают маленькими кусками, охватывая всего одно, два или три слова за одну остановку (фиксацию) глаз. До тех пор, пока кто-то читает вот этим последним дробным способом, он не преуспеет в увеличении скорости чтения; более длинные, чем, скажем, в одно предложение, мысли оказываются рассеченными на большое количество маленьких кусков, что затрудняет формирование единого, точного понимания смысла фрагмента текста.
Как мы уже знаем, интегральный алгоритм чтения облегчает поиск нужной информации в тексте в целом. Для каждого отдельного предложения и абзаца подобную программу, конечно, составить нельзя.
Однако для активизации чтения нужно заранее знать, что прежде всего следует отыскивать в каждом смысловом отрезке текста. Для этого и разработан дифференциальный алгоритм
чтения.
С его помощью можно разбивать каждый формально самостоятельный фрагмент текста на логические отдельные элементы (потому алгоритм и назван дифференциальным). Под отдельным логическим отрезком текста в данном случае мы понимаем каждый смысловой его абзац. Следует помнить, что печатный и смысловой абзацы могут не совпадать.
Для облегчения последующей работы рассмотрим каждый из блоков алгоритма отдельно (см.
рис. 13).
Ключевые слова несут основную смысловую нагрузку. Они обозначают признак предмета, состояние или действие. К ключевым словам не относятся предлоги, союзы, междометия.
Очень редко выступают в этой роли и местоимения, которые лишь замещают уже употребляемое ранее в тексте предметное (ключевое) слово. Очень часто смысловой абзац текста в целом является вспомогательным и вообще не содержит ключевых слов.
Смысловые ряды. Это пары слов, они состоят из комбинаций ключевых слов и некоторых определяющих и дополняющих их вспомогательных слов, которые помогают в сжатом виде понять истинное содержание абзаца.
Именно смысловые ряды являются основой золотого ядра содержания текста.
Таким образом, при чтении любого текста сознание соединяет ключевые слова в лаконичные, свернутые выражения смысловых рядов, несущие основной замысел автора. Текст как бы мгновенно сжимается, мысленно конспектируется.
В нем остаются только зерна мысли, золотое ядро на уровне непрерывных цепочек пар слов.
Но это только промежуточный этап. Ключевые слова и смысловые ряды выявляются в самом тексте, который пока претерпевает как бы количественные преобразования—сжимается, прессуется. Однако, кроме количественного анализа, сообщение всегда подвергается и качественному преобразованию.
Эта интеллектуальная операция соответствует третьему блоку алгоритма — выявлению доминанты.
Замечено, что содержание прочитанного при пересказе люди почти никогда не излагают слово в слово. Мозг перекодирует воспринятое сообщение в соответствии с собственным опытом, собственной программой.
Такое перекодирование происходит уже в самом процессе чтения. Этим как раз и отличается активное, осмысленное восприятие текста от механической
- Что же такое доминанта?
- Развитие смысловой догадки (антиципации)
- 6. Движение глаз при чтении
- Чтение с одновременным выстукиванием ритма
- Четыре фазы освоения упражнения с выстукиванием ритма